Reve 2.0とは|画像が"レイヤー分割"で生成される

「AIで画像は作れるけれど、出てきた1枚を後から直せなくて困っている」——LPやスライド、広告バナーをAIで作ろうとした経営者の多くが、この壁にぶつかります。
2026年6月3日に公開されたReve 2.0は、画像を最初から「レイヤー分割」された編集可能な構造で生成するという、画像生成AIの新しいアプローチを打ち出しました。本記事では、株式会社Fyveとして実際にReve 2.0を触った一次体験をもとに、この「レイヤー分割生成」が中小企業の制作実務を何から変えるのかを解説します。
結論から言えば、私はこれを「1枚絵の時代の終わり」だと受け止めています。なぜそう考えるのか、従来のフラットな画像生成との違いから順に見ていきます。
Reve 2.0とは|「触れる画像」を掲げる新モデル
Reve 2.0は、米パロアルトのReve AI, Inc.が2026年6月3日に公開した画像生成モデルです。公式は「世界最高の4K画像モデル」と表現し、キャッチコピーとして「For the first time, it's possible to create images you can touch(はじめて、触れる画像を作れるようになった)」を掲げています。
客観的な指標としては、画像生成モデルを人間の評価で順位付けするArena.ai のText-to-Imageリーダーボードで総合2位(スコア1280)にランクインしました。前バージョンのv1.5から125ポイントの大幅な改善で、首位はOpenAIのGPT Image 2、3位はGoogleのNano Banana 2(Gemini系)という並びです。リソースで圧倒する巨大IT企業に、スタートアップが正面から食い込んだ格好です。
ただ、私が注目しているのは順位ではありません。Reve 2.0の本質は「画像をどう生成し、どう保持するか」という設計思想そのものにあります。
「1枚絵」から「レイヤー分割」へ|何が根本的に違うのか
これまでの画像生成AI——私が日常的に使ってきたgpt-image-2のようなモデルも含めて——は、プロンプトを入力すると「1枚のフラットな画像」を出力します。きれいに出ればそれで完成ですが、問題は「直したいとき」に起きます。
たとえばLPのヒーロー画像で「見出しの文言だけ変えたい」「ボタンの色だけ変えたい」と思っても、フラットな1枚絵では特定の箇所だけを編集できません。プロンプトを少し変えて全体を生成し直すと、今度は構図も人物も別物になってしまう。「9割は完璧なのに、残り1割のために全部を引き直す」——この非効率を、私は何度も経験してきました。
Reve 2.0はここを根本から変えています。公式の説明では、Reve 2.0は画像を「構造化されたレイアウト(区画+ラベル)」として生成・保持します。画像内の各要素が「位置・サイズ・その要素の説明」を持ち、ひとつひとつが個別に指定・編集できる対象になっているのです。Reveはこれを「画像をコードとして表現する(images as code)」「プログラム合成としての画像生成」と表現しています。
技術的には、数十億の注釈付き画像で学習した「Large Layout Model」が土台にあり、計算負荷の重い拡散プロセスを、より効率的な「次のトークンを予測する問題」に変換しているとされます。難しく聞こえますが、利用者にとっての意味はシンプルです。生成された画像が、最初から「編集可能な部品の集まり」として出てくる——これがReve 2.0の核心です。
実際に触ってみた|美容サロンのヒーローセクション制作
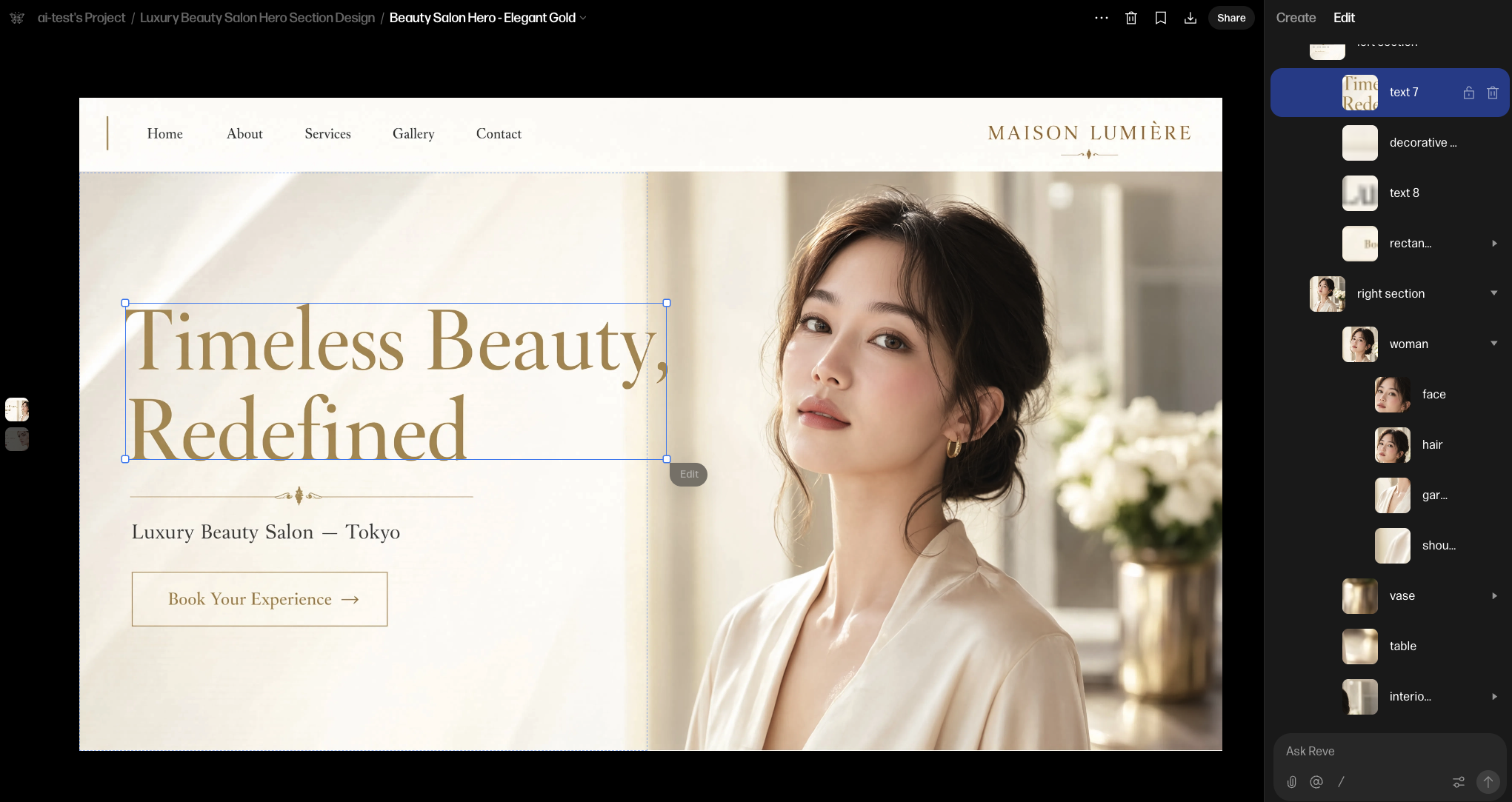
私が実際にReve 2.0で作ってみたのは、ある架空の高級美容サロンのトップページ用ヒーローセクションです。「Timeless Beauty Redefined」という見出し、モデルの写真、「Book Your Experience」というCTAボタンが配置された、いかにもLPに使えそうなビジュアルが生成されました。
感心したのはここからです。生成後の画面には、PhotoshopやFigmaのようなレイヤーツリーが表示されていました。「見出しテキスト」「装飾」「右セクション」、そしてその中に「人物」→「顔」「髪」「手」、さらに「背景のインテリア」……といった具合に、1枚に見えるビジュアルが、最初からきれいに部品分解されているのです。
これを見た瞬間、私が直感したことがあります。「生成した画像が最初からコンポーネントに分かれていて、それぞれが画像生成されて重ね合わされている構成なのか」と。つまり、後処理でマスクを切って分離しているのではなく、生成の出発点が部品単位なのです。だから「顔だけ」「見出しの文言だけ」「ボタンの色だけ」を、構図を壊さずに触れる。第三者のレビューでも、オブジェクトを直接クリックして動かせるドラッグ&ドロップ編集や、影・反射・パースまで整合させる空間理解が報告されています。
正直に言うと、私はこれで「もうimage-2から作ったものをpptxやMarpに流し込むようなパイプラインは要らなくなる」と感じました。これまで画像生成と編集可能性は別の工程でしたが、Reve 2.0はそれを一体化させてきたからです。
なぜ中小企業の制作実務を変えるのか
では、これが私たちのような中小企業の実務に何をもたらすのか。私が特に効くと見ているのは、次の3領域です。
LP(ランディングページ)制作
見出し・サブ見出し・CTAボタンの文言まで、画像内に正確な文字でレンダリングされたヒーロー画像を作れます。多くの画像生成AIが苦手としてきた「文字化け」が起きにくく、しかも同じ構図・スタイルのまま文言だけ差し替えたA/Bテスト用バリエーションを短時間で量産できます。「キャッチコピー3案を同じデザインで並べて比較したい」という、LP制作で最も頻繁に発生する要求に直接応えてくれます。
スライド・提案資料
大きく鮮明なタイトル、ラベルが正しく読める図解、ブランドを統一したセクション扉——こうした「文字を含む図版」は、これまでフラットな画像生成では作りにくい領域でした。レイヤー分割なら、テキスト部分だけを後から調整できるため、1枚作って終わりではなく、シリーズとして整えていけるのが強みです。
広告バナー
ディスプレイ広告やSNS広告は、複数サイズ・複数コピーで出稿するのが当たり前です。見出し・ロゴ・CTAを正確な文字で配置でき、オファー文言だけを差し替えられるReve 2.0は、CanvaやPhotoshopでの後処理を前提としないバナー制作を可能にします。「文字を含む本番アセットにそのまま使える」という点が、X上でも最大の差別化として繰り返し語られていました。
これら3領域に共通するのは、「人間が適切に命令しきれない」というボトルネックの解消です。フラットな1枚絵では、修正意図を毎回ゼロからプロンプトに翻訳し直す必要がありました。レイヤー分割なら「この部品をこう直す」と部分的に指示できる。人間の頭の中にある修正イメージと、AIの出力との間のギャップが、構造のレベルで縮まるのです。
私自身、これまでgpt-image-2でLPや提案書、スライドを量産してきましたが、その延長線上にある「次の形」がこれだと考えています。フラット画像生成でLPを作る具体的な手順は、以下の記事で解説しています。

冷静に見た限界|過度な期待は禁物
ここまでの可能性は本物だと考えていますが、案件で使う以上、限界も正直に押さえておきます。
- 有機的で複雑な被写体は苦手:第三者の詳細レビューでは、群衆や動物の毛並み、複雑な物理現象といった「有機的な細部」で精度が落ちると指摘されています。「リアリズムか複雑性のどちらかは出せるが、両立は難しい」という評価が複数のソースで共通していました。フォトリアルな実写の代替には、まだなりません。
- 公開直後で評価が出そろっていない:Reve 2.0は2026年6月3日公開の新顔です。X上の反応は圧倒的に好意的ですが、その多くは初動の興奮で、腰を据えた実使用レビューはこれからです。「期待先行の高評価」という側面は割り引いて見るべきです。
- モデレーションの強さ:「前バージョンより検閲が重く感じる」という不満の声が一部にありました。生成できる表現の幅は、実際に試して確かめる必要があります。
- 料金が確定情報として出そろっていない:月額プランのクレジット数は公開されていますが、消費者向けの具体的な月額料金は本記事執筆時点で明確に確認できませんでした。公式APIも提供は数日後(6月中旬頃)の予定です。導入コストの試算は、最新の公式情報で確認してください。
つまり現時点でのReve 2.0は、既存のフラット画像生成を全面的に置き換えるものではなく、「文字を含む編集可能なデザイン素材」という用途で強い、補完的な選択肢と位置づけるのが妥当です。
中小企業はどう向き合うべきか
私たちが顧問先の経営者にお伝えしているのは、「新しいツールが出るたびに乗り換える必要はない。ただし、自社の制作工程のどこがボトルネックかを知っておくべきだ」ということです。
もし御社が「LPや広告バナーを社内で作りたいが、文字入りのデザインで毎回つまずく」「外注のたびに修正のやり取りで時間がかかる」という課題を抱えているなら、Reve 2.0が打ち出したレイヤー分割生成という方向性は、近い将来あなたの制作実務を変える可能性が高いと私は見ています。
重要なのは、Reve 2.0という個別の製品名ではありません。「画像が最初から編集可能な部品として生成される」という流れは、今後ほかのツールにも広がっていくはずです。私たちはこうした技術の変化を、特定のツールに依存せず、御社の業務にどう活かせるかという視点で見続けています。
まとめ|画像生成は「1枚絵」から「編集可能な構造」へ
最後に、本記事の要点を整理します。
- Reve 2.0は2026年6月3日公開の画像生成モデル。Arena.ai のText-to-Imageリーダーボードで総合2位という客観評価を得た
- 最大の特徴は、画像を「構造化レイアウト(images as code)」として生成し、各要素を個別に編集できること。生成物が最初から「部品の集まり」として出てくる
- 従来のフラット画像生成の限界——「直したい箇所だけを直せず、全体を引き直す」非効率——を構造のレベルで解消する
- LP・スライド・広告バナーなど「文字を含む本番アセット」の制作実務に直接効く
- 一方で、有機的な実写は苦手、公開直後で評価が未成熟、料金が確定情報として出そろっていない、といった限界もある。フラット生成の置き換えではなく補完として捉えるのが現実的
画像生成は「きれいな1枚を引く」段階から、「編集できる構造を生成する」段階へと進み始めています。私たちはこの変化を、中小企業が現実の制作コストを下げるための道具として、引き続き検証していきます。
AIを使う会社と、使わない会社。
その差は、開き始めています。
ここ数年でAIは急速に進化し、正しく導入できている企業とそうでない企業とでは、業務効率や人件費に大きな差が生まれ始めています。「AI導入に興味はあるが、実際に何ができて、どこから手をつければいいか分からない」——そんな方は、まずこの無料プレゼントに目を通してみてください。
