Codexマルチエージェントv2|複数AIを並列で動かす

Codexで作業をしていて、「1つのタスクをやっている間、別のタスクも同時に進められたらいいのに」と感じたことはないでしょうか。コードの調査をしながら別の機能を実装し、その裏でテストも書く——人間なら当たり前にやっている並行作業を、AIエージェントにもさせたい。そう考える現場は増えています。
結論から言うと、2026年6月に更新された「マルチエージェント v2」によって、Codexは複数のエージェントを並列で走らせる運用が以前より格段に扱いやすくなりました。スレッドごとに実行環境(runtime)を選べるようになり、子エージェントのメタデータや追従(フォローアップ)の挙動も整理されています。
株式会社Fyveは、AI業務効率化の受託開発と専属AI活用顧問サービスを提供しています。代表の田嶋自身がCodexを日々の実務で使っており、本記事では私たちが実際に検証した範囲をもとに、マルチエージェント v2 の仕組みと、中小企業の現場で現実的にどう活かせるか・どこに注意すべきかを整理します。
Codexのマルチエージェントとは何か
まず前提として、Codexの「マルチエージェント(サブエージェント)」とは、1つのメインのエージェント(親)が、別のエージェント(子)を呼び出して作業を分担させる仕組みです。OpenAIは2026年3月16日にサブエージェント機能を正式に公開し、複数の作業を並列で実行できるようにしました。
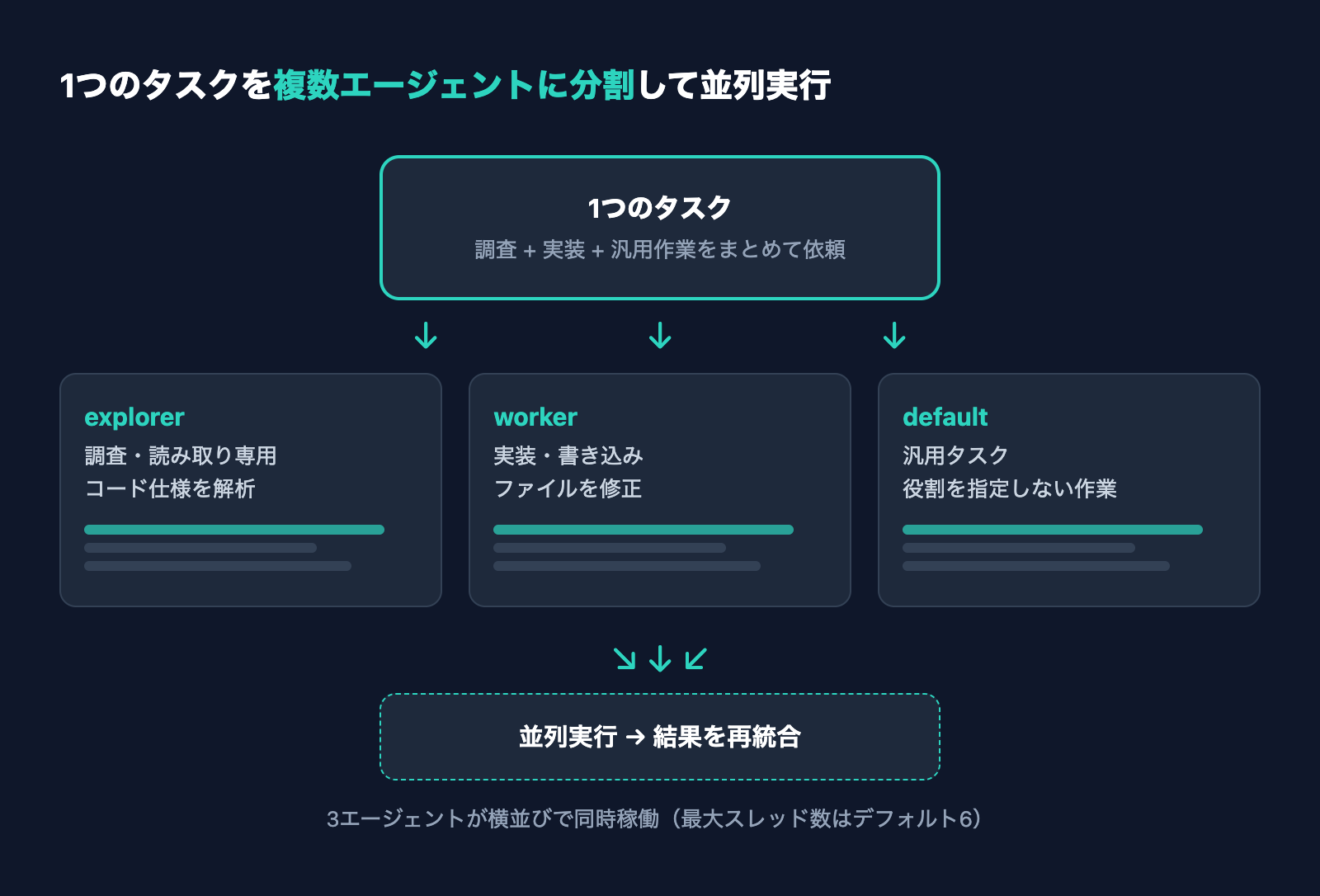
Codex CLIには、最初から3種類の組み込みエージェントが用意されています。それぞれ役割(ロール)が分かれており、タスクの性質に応じて使い分ける設計です。
- default: 一般的な作業向けの標準エージェント。役割を特に指定しない汎用タスクに使う
- worker: 実装・修正など、ファイルへの書き込みを伴う実行中心の作業向け
- explorer: コードベースの調査・読み取り中心の作業向け(読み取り専用の分析に適する)
探索は読み取りだけ、実装は書き込みあり、という形で権限と役割を切り分けられるのがポイントです。調査担当のエージェントには余計な書き込み権限を渡さない、といった安全な分業が自然にできます。
並列で動く台数の上限
同時に開けるエージェントのスレッド数には上限があります。設定の agents.max_threads で同時に開けるスレッドの最大数を決め、未設定時のデフォルトは6です。つまり標準では、親を含めて最大6本のスレッドを並行して走らせられる、という理解になります。
また、ネスト(入れ子)の深さは agents.max_depth で制御され、デフォルトは1です。ルートのセッションが深さ0で、直接の子エージェントが1つ下まで生成できる、という意味です。これは「子が孫を、孫がひ孫を…」と際限なく再帰的に増殖するのを防ぐための安全装置です。再帰的な委譲が本当に必要な場合だけ、この値を上げます。
マルチエージェント v2(2026年6月更新)で何が変わったか
2026年6月のアップデートで導入された「マルチエージェント v2」の中核は、スレッドごとに実行環境(runtime)の選択を保持するようになった点です。あわせて、生成(spawn)された子エージェントの追従とメタデータのデフォルトがより整理されました。
もう少しかみ砕くと、変更点は次のように整理できます。
- スレッド単位の runtime 保持: それぞれのスレッドが自分の実行環境の選択を持ち続ける。タスクごとに環境を切り替えながら並列実行しやすくなった
- 親の実行時オーバーライドの引き継ぎ: Codexは子エージェントを生成する際、親ターンのライブな実行時設定(runtime override)を再適用する。これにはセッション中に設定したサンドボックスや承認(approval)の選択が含まれる
- 追従とメタデータのデフォルト整理: 生成された子エージェントについて、フォローアップ(追加の指示や続きの処理)とメタデータの初期設定がよりクリーンになった
実務的に大きいのは2つ目です。セッション中に「このサンドボックスで」「この承認ポリシーで」と決めた設定が、子エージェントにもそのまま引き継がれます。親で安全側に絞った権限が、子で勝手に緩むことがない——並列で多数のエージェントを走らせるうえで、これは安心材料になります。

子エージェントを追いやすくするUI改善
並列でエージェントを走らせると、「今どれがどの作業をしているのか分からない」という問題が起きがちです。v2前後のアップデートでは、この見通しの悪さを解消する改善も入っています。
- ニックネーム: サブエージェントに分かりやすい呼び名が付くようになり、どのエージェントが何をしているか追いやすくなった
- ピッカーUIの整理: エージェントを選ぶ画面(picker)がよりクリーンになった
- 子スレッドの承認プロンプトの可視化: 子エージェントが承認を求めるプロンプトが見えるようになり、複雑な並列作業の管理がしやすくなった
CSVから作業を一括で割り振る
並列実行と相性がいいのが、CSVを使ったファンアウト(fan-out)です。spawn_agents_on_csv という機能を使うと、CSVの各行を1つの作業単位として複数のエージェントに振り分けられます。進捗トラッキングや完了見込み(ETA)の表示も組み込まれています。
CSVファンアウト時の1ワーカーあたりのタイムアウトは agents.job_max_runtime_seconds で既定値を設定でき、個別の呼び出しで max_runtime_seconds を指定するとそちらが優先されます。「100件のデータを順番に処理する」ような定型作業を、複数エージェントで分担して一気に片付けたいときに向いた仕組みです。
 読者特典・無料ダウンロードCodexに「課金」する前に読む本無料でダウンロード →
読者特典・無料ダウンロードCodexに「課金」する前に読む本無料でダウンロード →業務で並列エージェントをどう活かすか
ここからは、私たちが現場で考えている現実的な活用イメージです。マルチエージェントは「すべてを速くする魔法」ではなく、独立して進められる作業が複数あるときに効きます。
たとえば、以下のような場面では分割並列が素直にハマります。
- 調査と実装の分離: explorer に既存コードの仕様を読み解かせつつ、worker に別ファイルの実装を進めさせる
- 独立した複数機能の同時実装: 互いに依存しない機能AとBを別々のエージェントに割り振る
- 定型データの一括処理: CSVファンアウトで、行ごとに同じ処理を並列で流す
- 横断的な調査: 複数の観点からコードベースやドキュメントを並行して調べる
逆に、処理に強い前後関係がある作業(Aが終わらないとBが始められない)を無理に並列化しても、待ち時間が増えるだけで効果は出ません。まず「この作業は本当に独立しているか」を見極めるのが、並列化の最初の一歩です。

中小企業が押さえるべき注意点
並列エージェントは強力ですが、無計画に台数を増やすと逆効果になる側面もあります。私たちが顧問先に伝えているのは、次のような勘所です。
コストと予測可能性のリスクを見落とさない。 max_threads は同時に開くスレッド数の上限を決めますが、それだけでは深い再帰によるコストや予測しづらさのリスクは消えません。エージェントが増えれば、その分だけ計算資源と利用料がかかります。「並列にすれば速い・安い」という単純な話ではなく、台数と深さは意図的に絞るのが基本です。
権限の引き継ぎを理解しておく。 v2では親の承認・サンドボックス設定が子に再適用されます。これは安全側の挙動ですが、裏を返せば「親で緩めた設定が子にも伝わる」ということでもあります。最初に親セッションでどう権限を設計するかが、並列全体の安全性を決めます。
最新の正式情報で確認する。 マルチエージェント関連の機能名・設定値・デフォルトは更新が速い領域です。本記事の内容は2026年6月時点の確認ですが、設定値や挙動の詳細は導入前に必ず最新の公式ドキュメント(Configuration Reference・Subagents・Changelog)で確認してください。
実際に並列エージェントを動かす流れ
AI-firstの考え方では、コマンドを丸暗記するのではなく、やりたいことを言葉でCodexに伝えるのが基本です。並列で動かしたいときも、まずは自然言語で意図を渡します。
たとえば、Codexにこう頼むイメージです。
- 「この機能の調査は読み取り専用のエージェントに任せて、実装は別のエージェントで並行して進めて」
- 「このCSVの各行について同じ整形処理を、複数エージェントで分担して実行して」
- 「探索担当・実装担当・テスト担当に分けて、それぞれ並列で動かして」
そのうえで、組織として安定運用したい場合は、カスタムエージェントを定義しておく手もあります。~/.codex/agents/(個人用)または .codex/agents/(プロジェクト単位)にエージェントごとのTOMLファイルを置くと、自社の業務に合わせた役割をあらかじめ用意できます。
各TOMLファイルには name(名前)・description(どんなときに使うかの説明)・developer_instructions(振る舞いを定義する中核指示)を記述します。model や sandbox_mode などの任意項目は、省略すると親セッションから引き継がれます。「専用エージェントは作りたいが、細かい設定は親に合わせたい」というときに扱いやすい設計です。
よくある質問
Q. マルチエージェント v2 と、それ以前のサブエージェントは別物ですか?
別の機能というより、同じサブエージェント機能の進化版です。サブエージェント自体は2026年3月16日に正式公開され、2026年6月の「v2」で、スレッドごとの runtime 保持や、子エージェントのメタデータ・追従のデフォルト整理といった改善が加わりました。基本構造(default/worker/explorer の3ロール)はそのままに、並列運用の扱いやすさが上がった、と理解するのが正確です。
Q. 同時に何台までエージェントを並列で動かせますか?
標準では同時に開けるスレッド数の上限(agents.max_threads)が6で、未設定時はこの値が使われます。ネストの深さ(agents.max_depth)はデフォルト1です。台数や深さは設定で変更できますが、コストと予測可能性の観点から、必要以上に増やさないのが基本方針です。最新のデフォルト値は公式の設定リファレンスで確認してください。
Q. 子エージェントに余計な権限が渡らないか心配です。
v2では、親ターンの実行時設定(サンドボックスや承認の選択)が子エージェントを生成する際に再適用されます。つまり、親セッションで安全側に絞った設定が子にも引き継がれる挙動です。逆に親で緩めれば子にも伝わるため、最初に親セッションの権限設計を丁寧に行うことが重要です。explorer を読み取り専用の調査に充てるなど、役割と権限を対応させる運用が安全です。
Q. プログラミングが分からない管理者でも使えますか?
並列実行の「仕組み」を理解しておくことは役立ちますが、実際の操作はコマンドの暗記ではなく、自然言語での指示が中心です。「調査と実装を分けて並行で進めて」と伝えれば、Codex側が適切なエージェントに振り分けます。ただし、権限設計やコスト管理は組織として方針を決めておくべき部分なので、導入初期は社内の技術担当やパートナーと一緒に設計するのが現実的です。
Q. どんな作業を並列にすると効果が出ますか?
互いに依存しない独立した作業が複数あるときに効果が出ます。たとえば「調査」と「別ファイルの実装」、依存関係のない複数機能の同時実装、CSVの行ごとの一括処理などです。逆に、前の処理が終わらないと次に進めない直列的な作業を無理に並列化しても、効果はほとんど出ません。
Q. CSVを使った一括処理とは具体的に何ですか?
spawn_agents_on_csv という機能で、CSVの各行を作業単位として複数エージェントに振り分けられます。進捗トラッキングと完了見込み(ETA)の表示が組み込まれており、1ワーカーあたりのタイムアウトも設定できます。同じ処理を多数のデータに対して繰り返す定型作業を、分担して一気に処理したいときに向いています。
Q. 導入にあたって最初に何を決めるべきですか?
まず「どの作業を並列化するか(独立して進められる作業はどれか)」を切り分け、次に「親セッションの権限設計(サンドボックス・承認ポリシー)」を決めることです。そのうえで、必要に応じてカスタムエージェントをTOMLで定義します。台数・深さは小さく始め、効果とコストを見ながら調整するのが安全です。
まとめ
本記事のポイントを整理します。
- Codexのサブエージェントは2026年3月16日に正式公開され、default / worker / explorer の3ロールで作業を分担・並列実行できる
- 2026年6月の「マルチエージェント v2」では、スレッドごとに runtime の選択を保持し、子エージェントのメタデータ・追従のデフォルトが整理された
- 子エージェント生成時に、親ターンのサンドボックス・承認設定が再適用される(安全側の挙動)
- 同時スレッド数の上限(max_threads)はデフォルト6、ネスト深さ(max_depth)はデフォルト1。コストと予測可能性の観点から増やしすぎない
- spawn_agents_on_csv でCSVの行ごとに作業をファンアウトでき、進捗・ETA表示やタイムアウト設定が使える
- 並列化が効くのは「独立した作業が複数あるとき」。直列の作業を無理に並列化しても効果は薄い
- 機能名・設定値・デフォルトは更新が速いため、導入前に最新の公式ドキュメントで確認する
関連記事
並列エージェントと組み合わせて、目標を渡して自律的に進めさせる使い方を知りたい方はこちらをご覧ください。

Codex CLIの全機能を体系的に押さえたい方は、こちらの解説記事が役立ちます。

そもそもOpenAI Codexとは何かから理解したい方は、こちらの完全ガイドをどうぞ。

Codexに「課金」する前に読む本

無料枠の限界・プランの選び方・元の取り方を実測で(全26ページ)
課金の答えは、料金表の読み比べからは出ません。無料枠でできること・できないこと、金額でなく「倍率」で覚えるプランの構造、Claude Codeとの二刀流で枠を使い切る配分まで——両方に課金して1人会社を回している実運用から公開します。
- 無料枠でできる3つ・できない5つの線引き
- 金額でなく「倍率」で覚えるプラン早見表
- 週1回30秒で回る使用量の管理ルール(コピペ可)
- Claude Codeとの二刀流——枠を使い切る係の割り当て
毎週金曜の無料ニュースレター「ひとりAI経営」の購読特典です。メール登録後すぐ、ダウンロードページのご案内が届きます。あわせて、AI活用に関するお知らせやお役に立てそうなご案内をお送りすることがあります。解除はいつでも1クリック。
御社の業務に合わせたCodex導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。