Claude Opus 4.8 ベンチマーク比較と実運用コスト

Claude Opus 4.8 のベンチマーク比較と実運用コストを、中小企業の業務活用視点で整理します。本記事は2026年6月2日時点のスナップショットです。ベンチマークの世界はいま「タスクごとに勝者が変わる混戦」に入っており、単純な「1位」だけでモデルを選ぶ時代は終わりつつあります。株式会社Fyveは中小企業のAI活用顧問として複数モデルを並行運用しています。私たちが日々判断している「どのモデルをいつ使うか」の基準を、公式数値・第三者ベンチ・運用コスト・現場体感の4軸でまとめました。
Claude Opus 4.8 の位置づけ|価格据え置きで性能が前進
Claude Opus 4.8 は2026年5月28日にリリースされた、Anthropic 最上位の汎用提供モデルです。前世代 Opus 4.7 と比較した最大の特徴は、API料金が完全据え置きのまま性能が引き上げられた点にあります。同時に Fast Mode(研究プレビュー)、Claude Code の dynamic workflows、Effort control 拡張、ミッドカンバセーション system messages の正式提供など、運用周りも一気にアップデートされました(Anthropic公式リリース)。
公式メッセージの中心は「raw intelligence」よりも「trustworthiness(信頼して任せられること)」です。AIに長時間タスクを丸投げするエージェント運用が前提になってきた市場環境を反映しています。私たちの顧問先でも、ChatGPT 的なチャット用途から「業務を代行させる」用途へとニーズが移っているため、この方向性は理にかなっています。
一方で、ベンチマーク・他社比較・運用コストの観点から見ると、Opus 4.8 のリリースは単純な勝利宣言ではありません。タスク別に勝者が変わる「混戦」が一層明確になったのが2026年6月初頭の状況です。数値で見ていきます。
公式ベンチマーク|エージェント領域と知識労働で頭ひとつ抜けた
まず Anthropic 公式が公表している主要ベンチマークを整理します。
公式が前面に押し出した指標
- Online-Mind2Web(computer-use / browser-agent): 84% — Opus 4.7 と GPT-5.5 をいずれも上回る
- OSWorld-Verified: 82.3% — OS操作系の標準ベンチで最高水準
- Legal Agent Benchmark: all-pass 標準で10%突破を達成した初のモデル
- Super-Agent benchmark: 全ケースを end-to-end で完遂した唯一のモデル。GPT-5.5 と同コストで上回る
- Artificial Analysis Intelligence Index: 61 — 第三者統合指標で150モデル中1位
注目すべきは、従来「賢さの代名詞」だった MMLU や GPQA Diamond の数値が公式ブログのテキスト部に出てこない点です。テキストで強調されているのは agentic 系・実務タスク系のスコアばかり。Anthropic が訴求軸を「賢さ」から「任せられる」へ意図的に寄せていることの表れです。
第三者・コミュニティで流通している比較数値
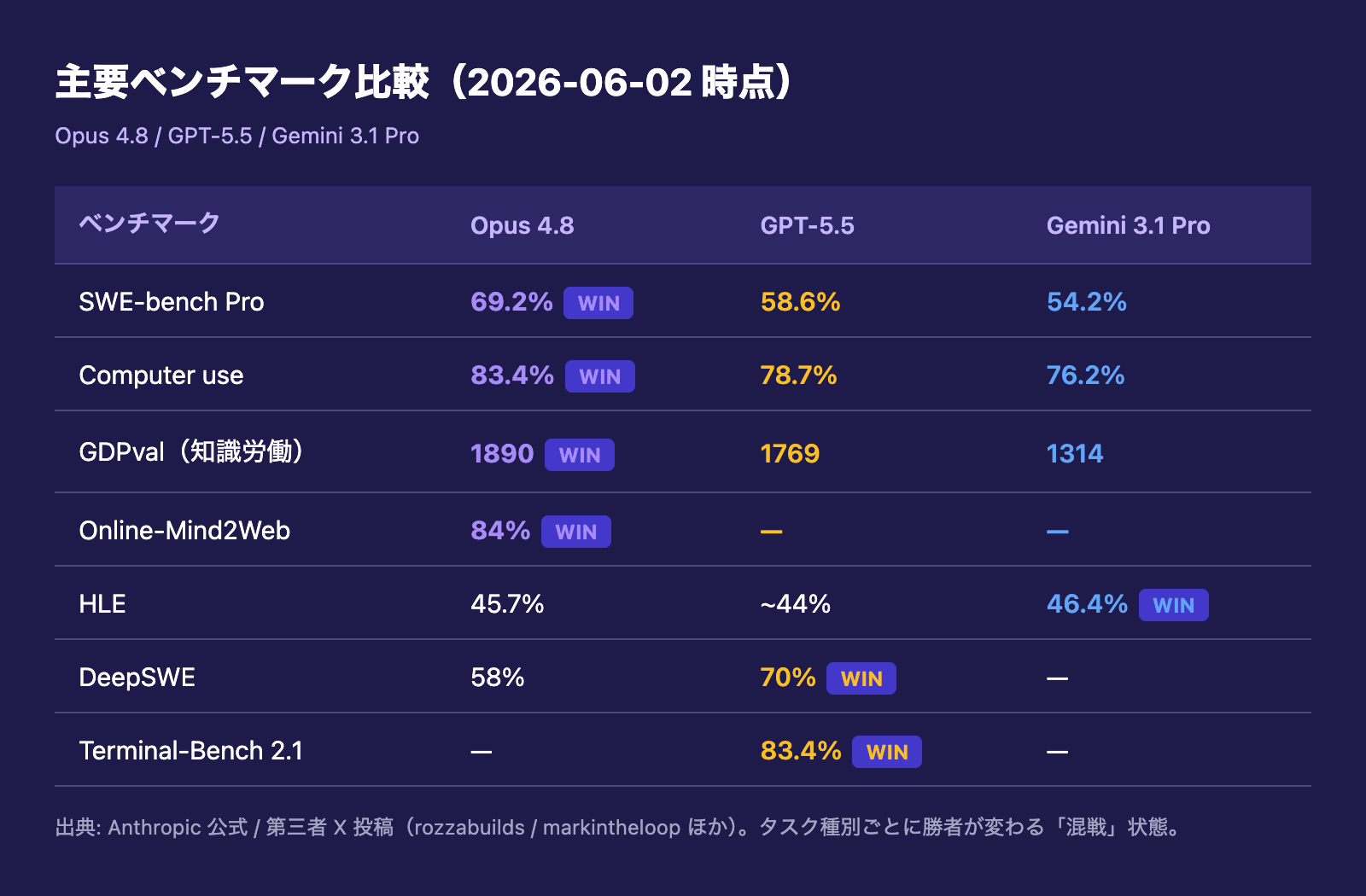
X や技術ブログ経由で流通している、Opus 4.8 と GPT-5.5・Gemini 3.1 Pro の比較数値を整理しました。
- SWE-bench Pro: Opus 4.8 が 69.2%(+4.9pt)、GPT-5.5 が 58.6%、Gemini 3.1 Pro が 54.2%(参考: rozzabuilds)
- SWE-bench Verified: Opus 4.8 が 87〜88.6%、harness 最大で 91.4%(参考: markintheloop)
- Computer use: Opus 4.8 が 83.4%、GPT-5.5 が 78.7%、Gemini 3.1 Pro が 76.2%
- GDPval(知識労働ベンチ): Opus 4.8 が 1890、GPT-5.5 が 1769、Gemini 3.1 Pro が 1314 — 圧勝
- HLE: Opus 4.8 が 45.7%(tools 有効時 57.9%)、GPT-5.5 が約44%、Gemini 3.1 Pro が 46.4% — 僅差で Gemini 勝ち
- DeepSWE: Opus 4.8 が 58%、GPT-5.5 が 70% — ターミナル系は GPT 優位
- Terminal-Bench 2.1: GPT-5.5 が 83.4% — Anthropic 公式画像内のみの数値ながら GPT 優位
Opus 4.8 が圧倒的に強いのは long-horizon agentic / computer use / 知識労働 です。一方で ターミナル系コーディング(DeepSWE、Terminal-Bench)では GPT-5.5 に水をあけられ、HLE のような最難関学術系では Gemini に僅差で負けています。「Claude が万能で1位」ではない、というのが2026年6月初頭時点の正確な現状認識です。
 読者特典・無料ダウンロードClaude Codeを「素のまま」使うな無料でダウンロード →
読者特典・無料ダウンロードClaude Codeを「素のまま」使うな無料でダウンロード →他社モデル比較|タスク別に「勝者」が違う混戦状態
ベンチ単体ではなく「実務でどう使い分けるか」という観点で、現時点の各モデルの得意領域・弱点を整理します。X 上のコンセンサスと、私たち自身の運用体感を統合した内容です。
主要モデルのポジショニング
- Claude Opus 4.8|得意: long-horizon なエージェント業務、構造的なコーディング、フロントエンド、computer use、知識労働。弱点: 純粋なターミナル系・バックエンドは GPT にやや劣勢
- GPT-5 / 5.5|得意: ターミナル系コーディング、バックエンド、バランス型の推論。弱点: 長時間自律エージェントは Opus 劣後
- Gemini 3.1 Pro|得意: high thinking 時の難関学術ベンチ、速度。弱点: computer-use・GDPval は劣勢
- Grok 4 系(4.1 / 4.3)|得意: xAI エコシステム内のリアルタイム X 検索、Grok-build 型タスク。弱点: 標準ベンチへの露出が少なく実務評価が定まっていない
「ベンチ好調」と「現場体感」の乖離
X 上では Opus 4.8 への賛否が明確に分かれています。ポジティブ側は「精度自体は劇的変化ではないが、わからない時にわからないと言える率が上がった」「honesty 4倍は実務で効く」といった声。一方ネガティブ側からは「huge regression だ」「Gemini よりハルシネートが多い」「ツールを使うのを拒否する」「1時間 Opus に書かせて2時間かけて幻覚コードを掃除した」といった厳しい意見も出ています。
この乖離は「タスク種別と相性で評価が真逆になる」現象として整理できます。長時間エージェント・computer use・構造化されたコーディング業務ではベンチ通りに強く、曖昧な意図を汲ませる作業では「物分かりが悪い」と感じられがちです。中小企業の業務に当てはめると、「手順が明文化されている領域」では Opus 4.8 が最良の選択肢になり、「ふわっとした相談相手」用途では他モデルでも代替が利きます。
6月の続報リスクを織り込む必要
もう一点、本記事の前提として明示しておきたいのは「2026年6月中に各社の続報が観測されており、1週間で勢力図が覆る可能性がある」点です。Claude / GPT / Gemini / Grok いずれも次バージョンの噂が複数のリーク系アカウントから出ており、「今この瞬間の勝者」を固定的に語ること自体に限界があります。本記事の数値は2026年6月2日時点のスナップショットとして読んでください。
実運用コスト|Fast Mode・Batch・Caching を含めた3層設計
中小企業の経営判断に直結する運用コストを、API公式価格表に基づいて整理します(Anthropic 公式価格ページ)。
基本料金(per 1M tokens)
- Claude Opus 4.8: Input $5 / Output $25 / Cache Hit $0.50 — Opus 4.7 から完全据え置き
- Claude Opus 4.7: Input $5 / Output $25 / Cache Hit $0.50
- Claude Sonnet 4.6: Input $3 / Output $15 / Cache Hit $0.30
- Claude Haiku 4.5: Input $1 / Output $5 / Cache Hit $0.10
Opus 4.1($15/$75)と比較すると 1/3 の価格を維持している点も重要です。フラッグシップの値段が世代を跨いで下がり続け、性能は上がっている構造は業務活用側に追い風です。
Fast Mode(研究プレビュー)
- Opus 4.8 Fast: Input $10 / Output $50(2.5倍速)
- Opus 4.6 / 4.7 Fast(旧世代): Input $30 / Output $150
Opus 4.8 Fast は従来世代比で約3倍安く、応答速度は2.5倍に短縮されています。Max プランの Claude Code はデフォルトで Fast Mode が適用されます(Fast Mode 公式ドキュメント)。対話的な業務、すなわち「人間が画面の前で結果を待っている」業務には Fast Mode が圧倒的に向きます。
Batch API(50%割引)
Opus 4.8 を Batch API 経由で利用すると、Input $2.50 / Output $12.50 に半減します。即時応答が不要な大量データの分類・要約・抽出には Batch を選ぶだけで運用コストが半分になります。月数千件のドキュメント処理を回す中小企業では、月数万円〜十数万円の差になります。
Prompt Caching(最大90%節約)
同じシステムプロンプトや長い参照ドキュメントを繰り返し使う運用では、Prompt Caching で最大90%のコスト削減が可能です。5分キャッシュなら1回、1時間キャッシュなら2回ヒットで元が取れます。Opus 4.8 では最小キャッシュ可能長が 1,024 tokens まで引き下げられたため、4.7 では届かなかった短めのプロンプトもキャッシュ対象になりました。
Data Residency オプション
米国限定の Data Residency を有効にすると、Input / Output / Cache 全てに +10% のサーチャージがかかります。Bedrock / Vertex の地域エンドポイントも同様に +10% です。米国データ滞留要件がある案件では、見積もり時にこの10%を織り込む必要があります。

「価格据え置き」の裏側にあるコスト構造リスク
API単価が据え置きでも、実運用では「2タスク回しただけで80ユーロ」「1セッションで $110+」「月 $200〜400 が普通になりつつある」という現場の声が X 上で観測されています(参考事例)。Opus 4.8 が得意な long-context / agentic 運用 ほどトークン消費が跳ねる構造的問題です。「価格据え置き」を真に受けて運用設計を雑にすると、月末に請求書で驚くことになります。
中小企業がモデルを選ぶ判断軸|3層使い分けが新標準
ここまでのベンチマーク・他社比較・コスト構造を踏まえて、私たちが顧問契約先に提案しているモデル選定の判断軸を整理します。
用途別の推奨モデル
- 長時間エージェント・複雑業務: Opus 4.8 — 性能対コストで現状最良。computer use や long-horizon タスクには他の選択肢が薄い
- 中規模コード生成・対話的分析: Opus 4.8 Fast — 3倍安・2.5倍速。人が画面の前で待つ用途では体感が劇的に変わる
- 単純繰り返し業務: Sonnet 4.6 — Opus の約60%のコスト。定型処理には十分
- 大量バッチ処理: Opus 4.8 Batch — 50%割引
- 短い反復プロンプト: Caching 活用で最大90%節約

「物分かり」と「制御可能性」の表裏一体
実体験ベースの所感を共有します。Opus 4.8 を Claude Code やエージェント業務で使うと、ある程度「物分かりが良くなった」と感じる場面はあります。ただし依然として、言葉の裏を読み取って勝手によしなにやってくれる方向は不得意なままです。
これは「言葉通り正確に動く = 制御可能」という長所の裏返しでもあります。明示的に指示できる業務、手順がドキュメント化されている業務には極めて向きます。「察してほしい」用途には他モデルが合うこともあり、業務適性で評価が真逆になる性質を持ちます。
「とりあえず Opus 4.8 へ全移行」が答えではない
価格据え置きで性能が上がったので、既存 Opus ユーザーは黙って 4.8 へ移行する判断で問題ありません。ただし「全業務を Opus 4.8 に統一」が最適解とは限らない、というのが私たちの結論です。
- 定型業務まで Opus に流すと、コスト的に Sonnet で十分な領域でも単価が3倍弱になる
- 対話的用途で標準モードを使うと、Fast Mode を使う場合と比べて応答が遅く、UX が下がる
- バッチ処理を即時APIで叩くと、Batch の半額を取り逃がす
つまり「Opus 4.8 / Sonnet 4.6 / Fast Mode の3層使い分け」を業務単位で設計するのが、2026年6月時点で最も合理的な運用パターンです。これは前世代までの「Opus か Sonnet か」の二択時代から、選択肢が一段細かくなったことを意味します。
注意点|初期不具合と長期視点
移行コスト自体は低く、Anthropic 公式 SDK(Python / TypeScript / Go / Java / Ruby / PHP / C#)はすべて2026年5月28日の同日に Opus 4.8 へ対応済みです(API リリースノート)。4.7 → 4.8 の breaking change はなく、既存コードはそのまま動きます。
一方で、claude-code リポジトリには Opus 4.8 リリース直後から関連 issue が23本上がっており、ハルシネーション増加・ツール捏造・Bedrock 経由での thinking パラメータ regression・トークン過剰消費・false-green 退行といった初期不具合が散見されます。重要な業務に投入する場合は、2〜3週間ほど様子を見るか、影響範囲を限定して段階的に切り替える運用が無難です。
料金や運用設計をもう少し体系的に押さえたい場合は、関連記事も併せてご覧ください。



まとめ|数値で見る Opus 4.8 と中小企業の選定指針
Claude Opus 4.8 はベンチマーク上「全領域1位」ではなく、long-horizon agentic / computer use / 知識労働で頭ひとつ抜けた一方、ターミナル系 GPT・難関学術系 Gemini との混戦が明確化しているモデルです。価格は前世代据え置きで Fast Mode・Batch・Caching を組み合わせれば、用途別に大幅なコスト最適化が可能です。
中小企業の現場視点では「全業務を Opus 4.8 に置き換える」のではなく、Opus 4.8(重い業務)/ Sonnet 4.6(定型処理)/ Fast Mode(対話用途)の3層使い分けが現実的な最適解です。本記事は2026年6月2日時点のスナップショットなので、各社の続報が出るたびに選定基準は更新する必要があります。私たちもクライアントへの提案を都度アップデートしていく前提で運用しています。
Claude Codeを「素のまま」使うな

設定で差がつく——CLAUDE.md・権限・スキルの実物を公開(全24ページ)
素のClaude Codeは"優秀な新入社員"。仕事を教えるほど、自分専用になります。覚えさせる4点セット——会社の説明書(CLAUDE.md)・権限の柵・手順書(スキル)・フォルダの地図——を、1人会社の実運用からコピペで使える型つきで公開します。
- そのまま書き換えて使えるCLAUDE.mdの型
- お金と送信をAIに触らせない「3段階の柵」
- 1回教えたら何度でも動く、手順書のコピペ雛形
- AIが迷子にならないフォルダ構造の3原則
毎週金曜の無料ニュースレター「ひとりAI経営」の購読特典です。メール登録後すぐ、ダウンロードページのご案内が届きます。あわせて、AI活用に関するお知らせやお役に立てそうなご案内をお送りすることがあります。解除はいつでも1クリック。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。