Claude Codeナレッジ管理|セッション間で知見を失わない仕組み

Claude Codeを使っていて、こんな経験はないでしょうか。
- 新しいセッションを開くたびに「うちはPostgreSQLです」「Next.js App Routerです」と説明し直す
- 先週フィードバックしたはずのルールが、今週はもう反映されていない
- 過去に解決したバグと同じ問題を、また1から調べ始める
これは「AI amnesia(AI記憶喪失)」と呼ばれる現象です。Claude Codeのモデル自体は優秀ですが、セッションが変わると記憶がリセットされる。だから毎回、同じ説明を繰り返すことになります。
私は株式会社Fyveで複数のクライアント案件を回す中で、このAI amnesiaに何度も苦しめられました。この記事では、マークダウンファイルだけでClaude Codeに「プロジェクトの記憶」を持たせる仕組みを、実運用の設計図とともに共有します。
まずはマークダウン4ファイルから始められる
プロジェクトメモリの基本形は非常にシンプルです。RAGもベクトルDBも不要。マークダウンファイルを数個置くだけで、Claude Codeの挙動は劇的に変わります。
- key_facts.md:技術スタック、環境変数、API設定など。Claudeが設定値を「推測」するのを防ぐ
- decisions.md:設計判断の記録。「なぜこのライブラリを選んだか」を残すことで、矛盾した提案を防ぐ
- bugs.md:過去のバグと解決策。同じ問題を2度調べる時間をゼロにする
- issues.md:進行中の課題と完了したタスク。プロジェクトの時系列文脈を与える

これだけで、新セッションのたびに技術スタックを説明し直す必要はなくなります。Claude Codeは起動時にCLAUDE.mdを自動読み込みするので、ここから各ファイルを参照させる設計にすれば、セッション間の記憶が途切れなくなります。
4ファイルでは足りなくなった理由
ただし、実務でこの仕組みを半年以上回してみると、4ファイルの限界が見えてきました。
最初の問題はファイルの肥大化です。プロジェクトが進むにつれ、bugs.mdやdecisions.mdがどんどん長くなる。Claude Codeは長いコンテキストの中間部分の情報を見落としやすいことが研究でも示されており、せっかく書いた知見が無視されるケースが出始めました。
次の問題は分類の曖昧さです。「このフィードバックはbugs.mdに書くべきか、decisions.mdに書くべきか」と迷うことが増え、情報の置き場所がバラバラになりました。
そして最大の問題は、知見の蓄積が手動だったことです。セッションで得た知見を毎回自分でファイルに書き足す——この手間が地味に大きく、忙しいと書き忘れる。結局、記憶が断片的になっていました。
 読者特典・無料ダウンロードひとりAI経営 全体マップ無料でダウンロード →
読者特典・無料ダウンロードひとりAI経営 全体マップ無料でダウンロード →多層ナレッジ設計:振り分けテーブルという発想
これらの課題を解決するために、私は知見の種類ごとに蓄積先を定義する「振り分けテーブル」を設計しました。
- 案件実績・エピソード → 実績・経験データベース(data/)
- AIツールの使用知見 → AI開発ツール知見データベース(data/)
- コーディング規約の変更 → rules/coding.md
- 記事執筆ルールの変更 → rules/article-writing.md
- ビジネス方針の変更 → rules/business-context.md
- 分類しにくい一時的な知見 → learnings/YYYY-MM.md(月単位で蓄積)
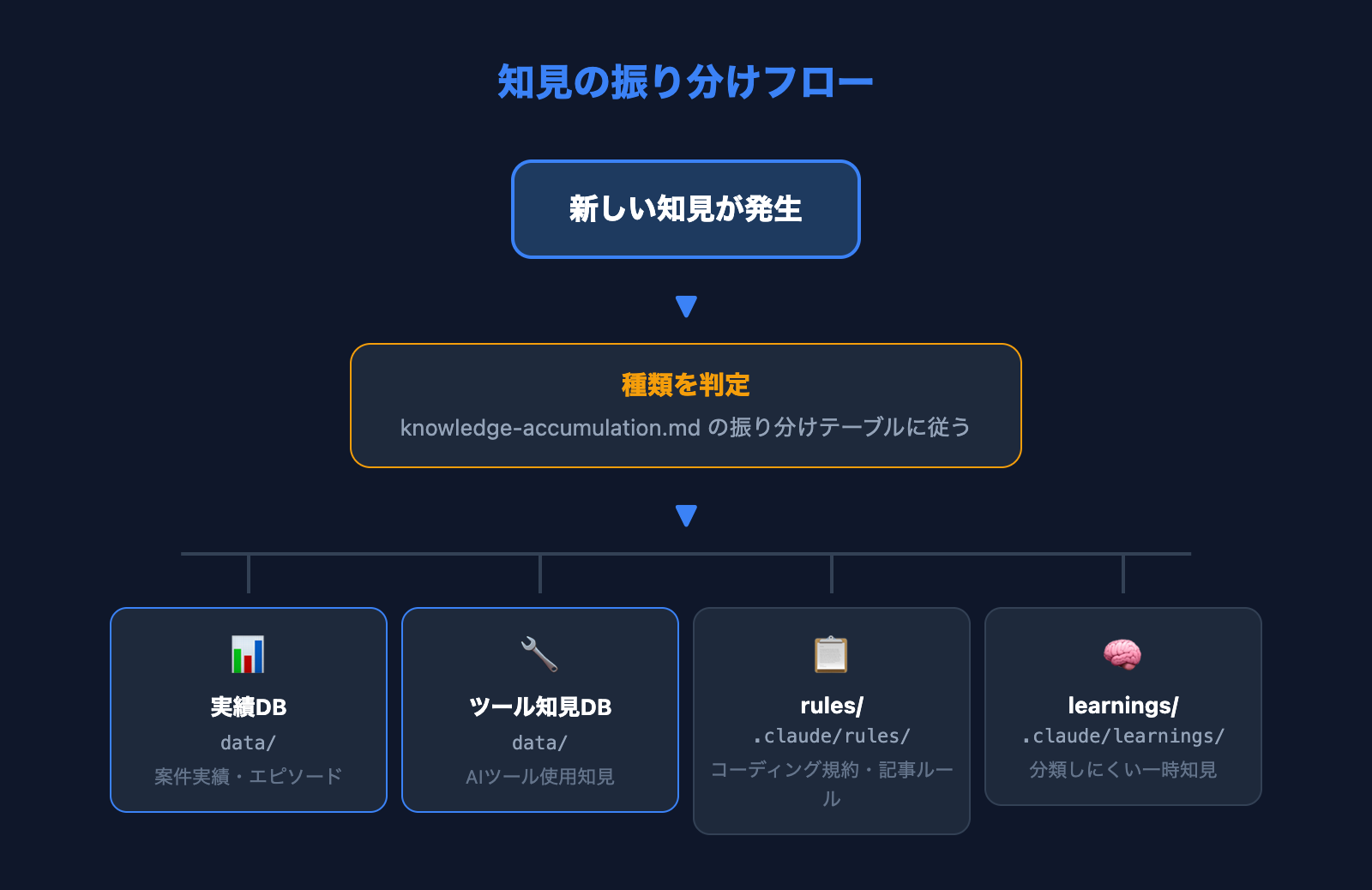
このテーブルをknowledge-accumulation.mdというルールファイルに定義しておくことで、Claude Code自身が「この情報はどこに保存すべきか」を判断できるようになります。4ファイルのフラットな構造から、目的別に整理された多層構造への進化です。
learnings/ → rules/への昇格フロー
多層設計の中で特に重要なのが、一時知見の受け皿であるlearnings/の運用です。
セッション中に得た知見のうち、すぐに分類できないものはlearnings/YYYY-MM.mdに一時保存します。各エントリには日付・カテゴリ(tech / business / feedback / debug / idea)・内容を記録。
そして月末に棚卸しを行います。
- 重要な知見 → rules/や正式なデータベースに昇格
- 不要な知見 → 削除
たとえば、セッション中に「この表記ルールを守って」とフィードバックした内容が、最初はlearnings/のfeedbackカテゴリに記録されます。月末の棚卸しで同じフィードバックが繰り返されていれば、rules/article-writing.mdに正式ルールとして昇格させます。
この「一時蓄積→棚卸し→正式ルール化」のフローによって、プロジェクトの知識が自然に整理・成長していきます。
自動蓄積:「答えたら即保存」の仕組み
振り分けテーブルだけでは、まだ一つ課題が残っていました。ヒアリングで得た情報の保存が漏れる問題です。
たとえば、SEO記事を書くために私の実体験をヒアリングしたとします。「この案件ではこういう課題があって、こう解決した」と答える。その情報は記事には反映されるのですが、データベースへの蓄積が抜け落ちることがありました。次に似たテーマの記事を書くとき、同じ質問をもう一度されることになります。
そこで、蓄積ルールに「ユーザーが質問に回答した場合も即追記する」という自動トリガーを追加しました。「保存して」と言われるのを待たず、一次情報を含む回答を受け取った時点で該当ファイルに自動追記する仕組みです。
これにより、ヒアリングで出た情報が自動的にデータベースに蓄積され、次回以降のセッションで即座に参照できるようになりました。手動の書き忘れがゼロになったのは、運用上の大きな転換点でした。
Auto Memoryの限界と補完策
Claude CodeにはAuto Memory機能があり、~/.claude/CLAUDE.mdにセッションの学びを自動記録してくれます。便利ですが、いくつかの限界があります。
- 振り分けができない:全てがグローバルCLAUDE.mdに書かれるため、プロジェクト固有の知見も全セッションに影響する
- 肥大化する:Auto Memoryが大きくなるほど、全セッションのコンテキスト消費が増える
- 構造化されない:フラットに追記されるため、情報の検索性が低い
対策として、Auto Memoryに任せきりにせず、前述の振り分けテーブルで明示的に蓄積先を定義しています。Auto Memoryは「補助的な記録」として残しつつ、プロジェクトの中核知見は構造化されたファイルに蓄積する。この二段構えが、現時点での最適解です。
過去に試した4つの方法と、Markdown管理を選んだ理由
この運用にたどり着くまでに、いくつかのアプローチを試してきました。失敗の経緯も含めて共有します。
方法1:メモリファイルだけに頼る——ほぼ機能しなかった
最初に試したのは、Claude Codeの自動メモリ機能(MEMORY.md)だけに頼る方法です。これだけではセッション間のコンテキスト維持はほぼ機能しませんでした。「何を覚えるか」の判断がAI任せになるため、本当に必要な情報が抜け落ちたり、逆に不要な情報が蓄積されたりします。プロジェクトの方針やルールのような「体系的な知識」を管理するには力不足でした。
方法2:Skill内に知識を埋め込む——管理が煩雑になった
次に試したのは、Skillsの中に関連知識を埋め込む方法です。例えば「SEO記事執筆スキル」の中に、記事の表記ルール・過去の記事一覧・キーワード戦略まで全部含める。一定の効果はありましたが、スキルが細分化されすぎて同じ情報が複数のスキルに重複し、ルールを1つ変更するたびに3〜4箇所を修正する事態になりました。知識の一元管理としては破綻していました。
方法3:Notion・Obsidian等の外部ツール連携——フォーマットの制約で断念
Karpathy氏やLlamaIndex創業者Jerry Liu氏が提唱する「AIの出力をObsidianに蓄積して第二の脳を作る」アプローチも検討しました。双方向リンクやグラフビューは魅力的です。
しかし、各ツールのフォーマットに合わせる必要があり、コンテキスト保持の形式を自由に決められないという壁にぶつかりました。Notionならブロック構造、ObsidianならフロントマターMarkdownと、ツール側の制約に引きずられます。「Claude Codeにとって最適な形式で知識を保持する」ことができず、この方針は撤回しました。
方法4:プロジェクト単位GitHub管理 + Markdown——現在の運用
プロジェクトのGitリポジトリ内にdata/フォルダを設け、Markdownファイルで知見を蓄積する方法です。Claude Code自身がファイルを直接読み書きでき、Skills・ルールファイルと一体運用できる。Git管理で履歴も残る。この構成にしてから、セッション間のコンテキスト維持の問題はほぼ解消しました。
Obsidianが向くのはどんなケースか
私はMarkdown管理を選びましたが、Obsidianが向くケースも明確にあります。
- 複数プロジェクト横断で知識を管理したい:個人の第二の脳として蓄積する用途
- 視覚的に関連性を把握したい:グラフビューで俯瞰する運用
- チームで共有する:Git不慣れなメンバーも含めて運用する場合
一方、プロジェクト内Markdownが向くのは「Claude Codeの精度を最大化したい」「Skillsやルールと一体運用したい」「Git履歴と複数端末同期の恩恵を受けたい」ケースです。重要なのは「どのツールか」ではなく「AIに何を覚えさせ、何を忘れさせるかの設計」です。
プロジェクト初期化のコツ|質問形式で聞き返してもらう
プロジェクトを新規で立ち上げた直後が最も重要です。最初のセッションでClaude Codeに覚えておいてほしいコンテキストを効率よく入力する必要があります。
私が実践しているのは、一方通行で情報を提供するのではなく、質問形式で聞き返してもらう方法です。Claude Codeに「このプロジェクトについて理解を深めるために質問してください」と依頼するだけです。
すると、以下のような構造的に必要な内容を逆算した質問が返ってきます。
- プロジェクトの目的は何か
- 目的を達成するために何が必要か
- どのデータを保存すべきか
- 何を定期的に行うべきか
この質問に答えていくだけで、プロジェクトの方針・構成・運用ルールが自然とCLAUDE.mdやルールファイルに整理されます。人間が「何を伝えるべきか」を考える負担が大幅に減るのがこの方法の利点です。
逆に、最初のセッションで箇条書きのメモを一気に貼り付ける方法は、情報の優先順位が不明確になりがちです。質問→回答の往復で構造化するほうが、結果的にClaude Codeにとって読みやすいドキュメントが生成されます。
プロジェクトの粒度設計|3つの軸
私は約6つのプロジェクトを並行運用しています。この「どこで分けるか」は意外と重要で、3つの軸で判断しています。
- トークン量の節約:1つのプロジェクトに全てを詰め込むと、CLAUDE.mdだけで膨大なトークンを消費する。関連性の低い情報は分離する
- コンテキストの維持:相互参照で出力品質が上がる部分は同一プロジェクトに置く。例:SEO記事執筆ルールと案件実績データは密接に関連するため同居
- 人間側の認識しやすさ:Claude Codeだけでなく、自分自身が「今どのプロジェクトで作業しているか」を直感的に把握できる粒度にする
同一にすべきものは、相互参照で品質が上がる組み合わせです。私の場合、Webサイト開発・SEO記事執筆・営業資料・ビジネスデータは同一プロジェクトにまとめています。記事を書くときに案件実績を参照し、営業資料を作るときにサービス体系を参照するためです。
分離すべきものは、方針やポジションが混合されると混乱の原因になるものです。独立したgitリポジトリで管理しているSaaS開発は、コーポレートサイトとは別プロジェクトにしています。技術スタックもデプロイ先も異なるため、同じCLAUDE.mdに同居させると指示が競合します。
複利で効く:使い込むほど精度が上がる
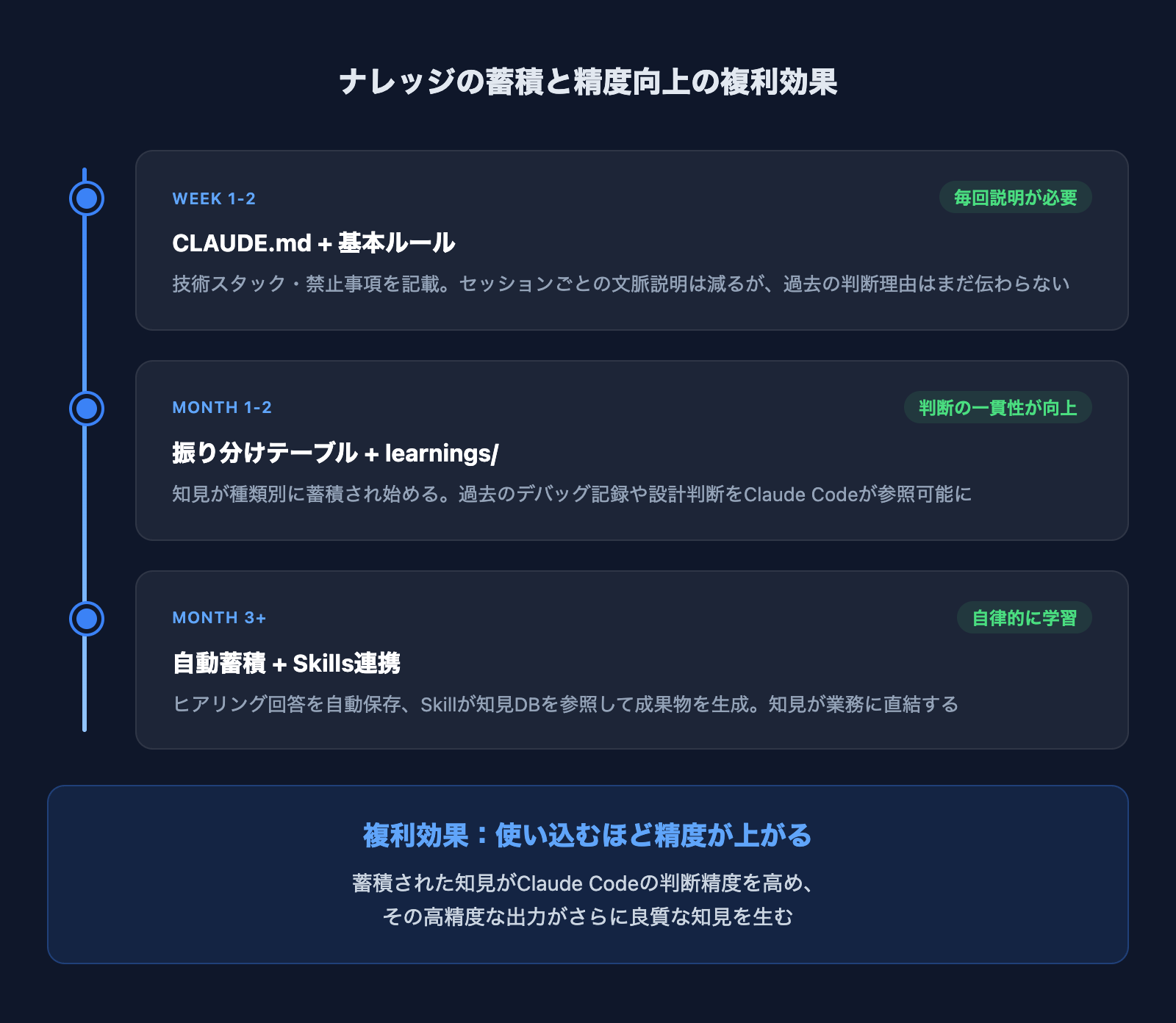
このナレッジ管理の仕組みで最も実感しているのは、複利効果です。
最初の1〜2週間は、CLAUDE.mdと基本ルールで「毎回の説明」を減らしただけでした。しかし1ヶ月、2ヶ月と知見が蓄積されるにつれ、Claude Codeの出力精度が目に見えて上がっていきます。
具体的な例を挙げると、SEO記事の執筆です。初期は毎回「田嵋の実績データベースを見て」「記事の表記ルールを確認して」と指示していました。今ではキーワードを渡すだけで、過去の実績を自動参照し、表記ルールを守り、既存記事との重複を避けた記事が出てきます。
蓄積された知見がClaude Codeの判断精度を高め、その高精度な出力がさらに良質な知見を生む。使い込むほどプロジェクトが「賢く」なっていく感覚は、まさに技術的負債の逆——ナレッジの複利です。
蓄積のルール:何を保存し、何を保存しないか
何でも保存すればいいわけではありません。知見蓄積には3つのルールを設けています。
- 一次情報のみ蓄積する:推測や一般論は保存しない。ユーザーから得た事実だけを記録する
- 重複させない:同じ情報を複数ファイルに書かない。メンテナンスの手間と情報の不整合を防ぐ
- 既存フォーマットを守る:追記する際は各ファイルの構造を壊さない。データベースの一貫性が命
また、知見ファイルが肥大化したらファイル分割やSkill内での必要部分だけの読み込みで対応します。トークン管理の詳細はMax 5xプランのレビュー記事で解説しています。
自己進化するのはモデルではなく、ハーネスである
ここまで読んで「Claude Code自体が賢くなっていくのでは?」と思う方がいるかもしれません。実感は逆です。変わったのはモデルではなく、ハーネス(CLAUDE.md・Skills・ルールファイル・知見データベースの総体)です。
新しいセッションを立ち上げるたびに、前回のセッションで蓄積された知見が反映され、ルールが改善され、スキルが磨かれている。この積み重ねが「同じプロンプトでも、先月より今月のほうが良い出力が出る」という体験を生み出しています。
知識管理は地味な作業です。しかし、この基盤がなければClaude Codeはただの「高性能だが記憶のないツール」のままです。セッション間で知識が引き継がれる仕組みを作ることが、Claude Codeを真に業務の中核として活用するための最も重要な一歩だと考えています。
まとめ:マークダウンだけでClaude Codeは「学習」する
Claude Codeのナレッジ管理に必要なのは、RAGでもベクトルDBでもありません。マークダウンと振り分けルールだけです。
- 4ファイルから始める:key_facts / decisions / bugs / issuesで基本的な記憶を持たせる
- 振り分けテーブルで多層化する:知見の種類ごとに蓄積先を定義し、構造化する
- learnings/ → rules/の昇格フローで知識を自然に成長させる
- 自動蓄積トリガーで手動の書き忘れをゼロにする
- 外部ツールよりClaude Code内完結を優先。Obsidianはチーム共有用途に限定する
- プロジェクト初期化は質問形式でClaude Codeに聞き返してもらう
- 粒度設計は3軸:トークン量・コンテキスト維持・人間側の認識しやすさ
- 進化するのはモデルではなくハーネスだと割り切る
設定ファイルの工夫だけで、Claude Codeは「使うたびに賢くなるツール」に変わります。あなたのプロジェクトでも、まずは4ファイルから試してみてください。
ひとりAI経営 全体マップ

AIエージェントで1人会社を丸ごと運営する、全業務の見取り図(全33ページ)
集客から経理まで、実在する1人会社の全業務を「何を・どのAIに・どこまで任せているか」の分担表つきで公開。8つの工程ごとに、実際に動いている仕組みと自動化度(10点満点)を正直に載せた、実運用そのままの全体地図です。
- 全業務 × 動かす仕組み × 自動化度(10点満点)の分担表
- 調査 → 集客 → 商談 → 経理まで、8工程の見取り図
- お金と対外送信をAIに触らせない「3段階ルール」
- 使用ツール早見表と、今日からの最初の一歩
毎週金曜の無料ニュースレター「ひとりAI経営」の購読特典です。メール登録後すぐ、ダウンロードページのご案内が届きます。解除はいつでも1クリック。
御社の業務に合わせたClaude Code導入支援
「AIツールを導入したが、現場で使われない」を終わらせる。
業務課題のヒアリングから設計、ハンズオン実践、運用定着まで一貫して支援します。