Hermes Agent Ollama ローカル運用完全ガイド|Gemma 4 × LM Studio で API コストゼロ【2026年版】

株式会社Fyveでは、クライアント環境に Hermes Agent を導入するとき「API コストを毎月いくら払うべきか」「機密データを外部 API に流して大丈夫か」という相談を必ず受けます。2026 年に入り Ollama 0.6 系と Gemma 4・Qwen3-Coder-Next が出揃ったことで、私たちは「軽量タスクはローカル、重要タスクだけクラウド」というハイブリッド構成を標準提案にしています。この記事では Hermes Agent を Ollama でローカル運用するための実装手順と、推奨モデル・ハードウェア・限界点を一気通貫でまとめます。
なぜ Hermes Agent をローカル LLM で動かすのか
クラウド API(Anthropic / OpenAI)を Hermes Agent から叩く構成は手軽ですが、業務に組み込むと 3 つの摩擦が出ます。私たちが実装現場で直面したのは次の点です。
- コスト:1 ユーザーあたり月 2〜5 万円が普通に飛ぶ。10 名の組織で月 30 万円超に膨らむケースもある
- 機密性:人事情報・カルテ・図面・ソースコードを外部 API に流すことに法務が首を縦に振らない
- レイテンシ:海外リージョンのモデルだと初回トークンまでに 1〜2 秒待たされる
- オフライン要件:閉域 LAN・現場端末・出張先のテザリングでも動かしたい
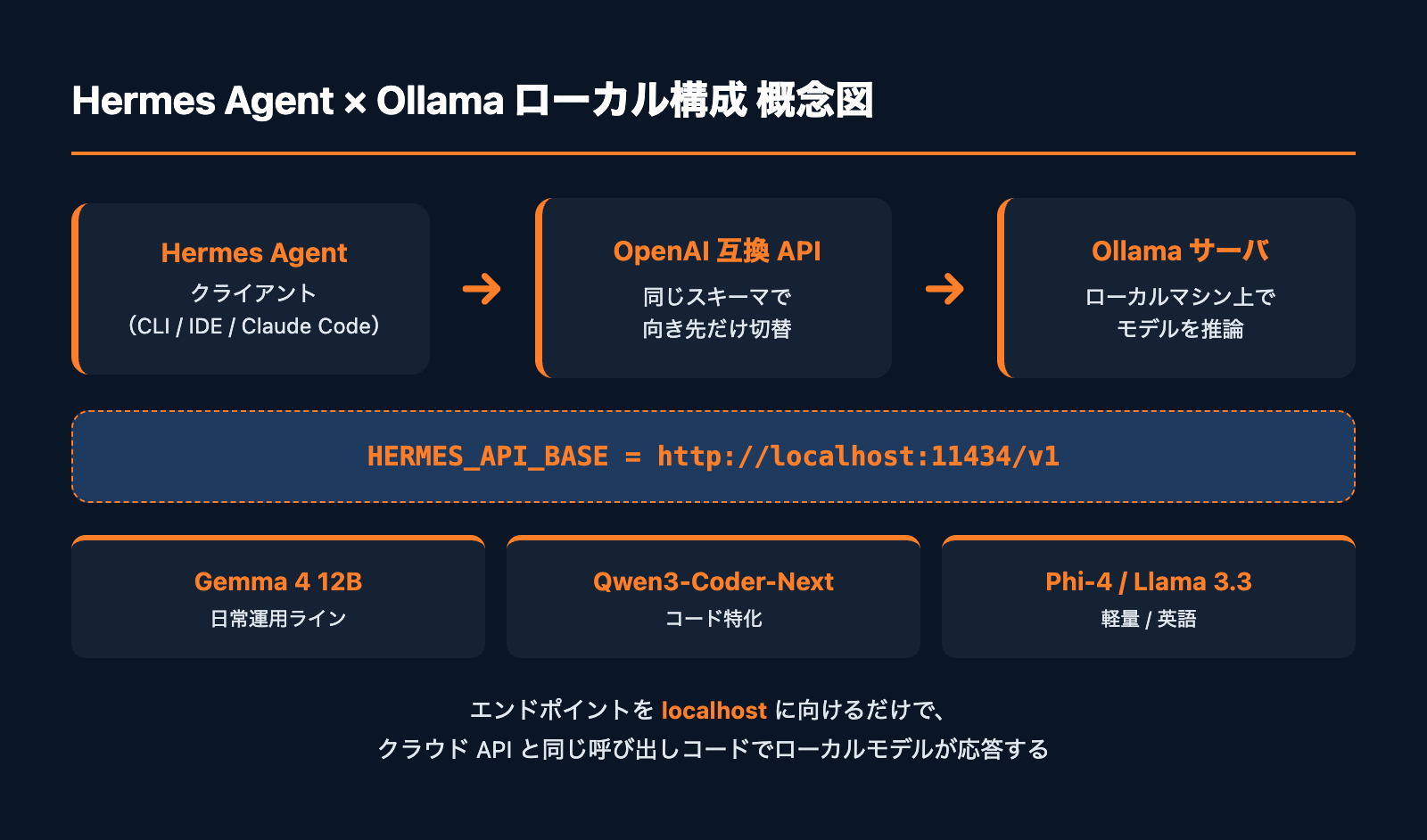
Ollama を挟むと、これらが一気に解消します。Hermes Agent は OpenAI 互換エンドポイントを叩けるので、向き先を http://localhost:11434/v1 に変えるだけでローカルモデルが応答するようになります。
Ollama の基礎セットアップ
2026 年 6 月時点の Ollama はインストーラ 1 つで完結します。Mac / Windows / Linux すべて同じ流れです。
# macOS
brew install ollama
ollama serve &
# モデルのダウンロード(Gemma 4 12B MLX 量子化)
ollama pull gemma4:12b-mlx
# 動作確認
ollama run gemma4:12b-mlx "自己紹介して"X 上で @ollama 公式が告知した ollama launch hermes --model gemma4:12b-mlx という新コマンドは、Hermes Agent をローカルモデル向きの初期設定で立ち上げてくれるショートカットです。私たちのチームでも検証用 Mac mini にこのコマンドで一発投入しています。
 読者特典・無料ダウンロードHermes Agentに「任せる」前に読む本無料でダウンロード →
読者特典・無料ダウンロードHermes Agentに「任せる」前に読む本無料でダウンロード →推奨モデル選定(2026 年 6 月時点)
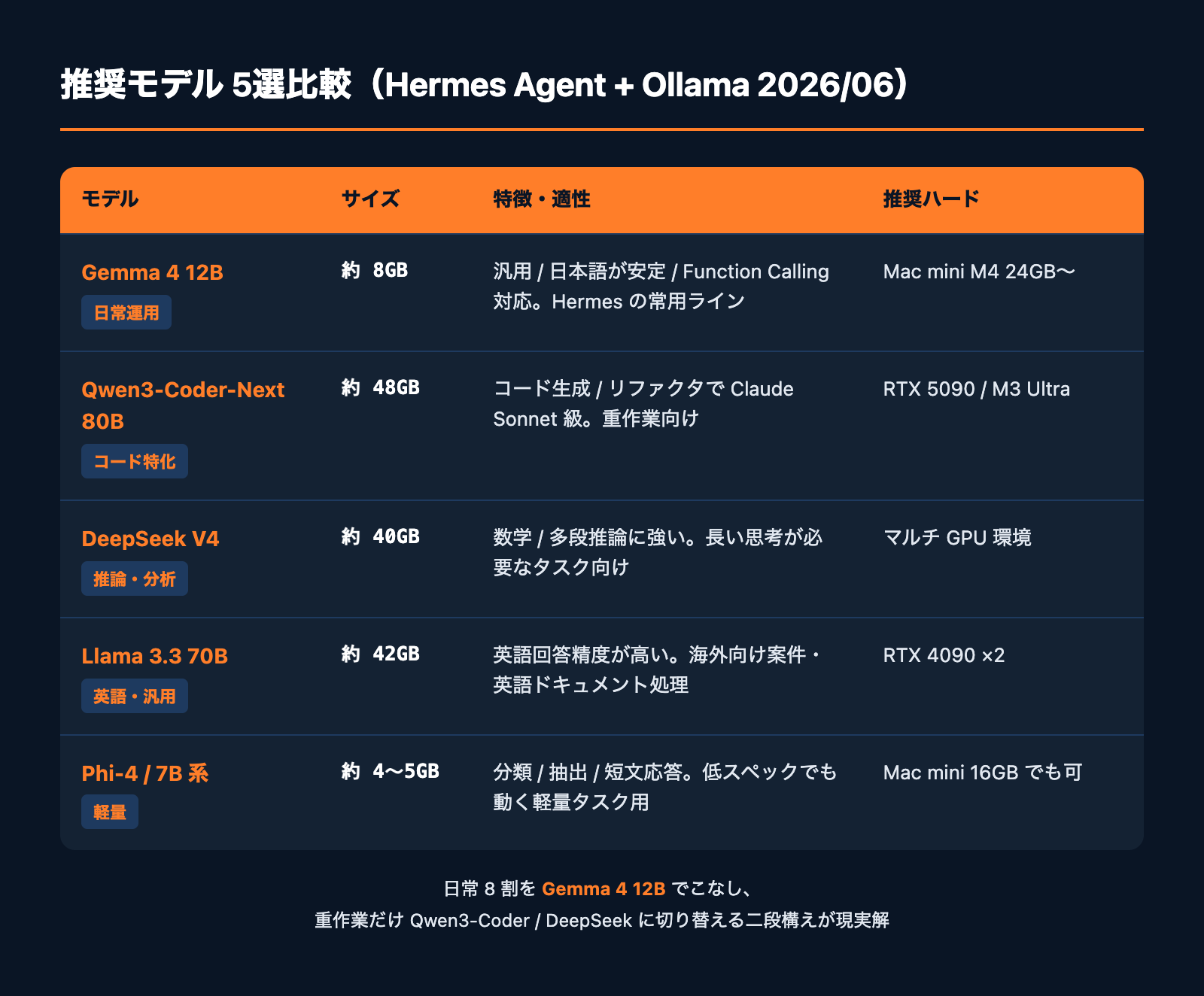
「Hermes Agent と相性が良いローカルモデル」を、私たちが社内検証した結果をベースに整理します。
モデル | サイズ | 得意領域 | 推奨ハード |
|---|---|---|---|
Gemma 4 12B(MLX) | 約 8GB | 汎用・日本語・関数呼び出し | Mac mini M4 24GB〜 |
Gemma 4 27B | 約 18GB | 長文要約・調査 | Mac Studio / RTX 4090 |
Qwen3-Coder-Next 80B | 約 48GB(4bit) | コード生成・リファクタ | RTX 5090 / M3 Ultra |
DeepSeek V4 | 約 40GB | 推論・数学・分析 | マルチ GPU 環境 |
Llama 3.3 70B | 約 42GB | 汎用・英語回答精度 | RTX 4090 ×2 |
Phi-4 / 7B 系 | 約 4〜5GB | 軽量タスク・分類・抽出 | Mac mini 16GB でも可 |
@Sentdex が紹介して話題になった Qwen3-Coder-Next 80B はコード生成では Claude Sonnet に肉薄しますが、80B クラスは現場の Mac mini ではほぼ動きません。私たちは「日常運用は Gemma 4 12B、コードレビューの重作業だけ Qwen3-Coder」という二段構えを提案しています。
Hermes Agent と Ollama の接続設定
Hermes Agent 側は環境変数だけで切り替えできます。プロジェクトルートの .env に次の値を入れます。
# OpenAI 互換エンドポイントを Ollama に向ける
HERMES_API_BASE=http://localhost:11434/v1
HERMES_API_KEY=ollama # ダミー値でOK
HERMES_MODEL=gemma4:12b-mlx
# Function Calling を使う場合
HERMES_TOOL_MODE=openai-compatible動作確認は次のコマンドで一発です。
hermes chat --model gemma4:12b-mlx --prompt "今日のタスクをまとめて"ポイントは HERMES_API_KEY がダミー値で構わない点です。@fahdmirza が広めた「zero cloud, zero API keys」構成は、まさにこの仕組みを指しています。
推論ハードウェア要件と体感速度

私たちが検証用に並べた 3 構成での実測値です。tokens/sec はチャット応答の体感に直結します。
環境 | モデル | tokens/sec | 用途感 |
|---|---|---|---|
Mac mini M4 16GB | Phi-4 / Gemma 4 8B | 25〜35 | 軽量タスク。会話・分類・抽出はサクサク |
Mac mini M4 24GB | Gemma 4 12B MLX | 40〜55 | 常用ライン。Hermes Agent の日常運用に最適 |
Mac mini M4 Pro 32GB | Gemma 4 27B | 20〜28 | 長文要約・社内ナレッジ検索向け |
RTX 4090 + Win11 | Llama 3.3 70B 4bit | 30〜45 | 英語タスク・大規模コード生成 |
RTX 5090 + Linux | Qwen3-Coder-Next 80B | 35〜50 | コード特化。Claude Code 代替に近い体感 |
Mac mini を中心としたコスト試算は Mac mini で Hermes Agent を運用するコスト試算【2026年版】 にまとめています。GUI 派には LM Studio もおすすめで、モデル切り替えをマウスでできるため、エンジニア以外のメンバーがいる現場では LM Studio + Ollama 並行構成にしています。
ハイブリッド戦略:ローカルとクラウドの使い分け
「全部ローカル」も「全部クラウド」も極端で、現実解はハイブリッドです。私たちはタスクを 3 層に分けて振り分けています。
- ローカル(Gemma 4 12B):定型応答・要約・分類・社内文書 RAG・チャット履歴整形
- ローカル重量(Qwen3-Coder / Gemma 4 27B):コードリファクタ・長文要約・社内ナレッジ深掘り
- クラウド(Claude / GPT):提案書ドラフト・複雑な要件定義・最終アウトプットの整形
料金の全体像と「どこまでクラウドに払うべきか」は Hermes Agent 料金・コスト完全ガイド に整理しています。機密性視点での運用ルールづくりは Hermes Agent セキュリティ監査 7826 項目チェック も合わせて参照すると判断しやすいです。
セットアップ手順(実コマンドまとめ)
新規端末でゼロから組む場合の最短ルートです。Mac mini M4 24GB を想定しています。
# 1. Ollama インストール
brew install ollama
# 2. サービス起動(launchd登録)
brew services start ollama
# 3. 主要モデルを pull
ollama pull gemma4:12b-mlx
ollama pull phi-4:14b
# 4. Hermes Agent インストール
npm i -g @hermes/agent
# 5. 環境変数設定
cat << 'EOF' >> ~/.zshrc
export HERMES_API_BASE=http://localhost:11434/v1
export HERMES_API_KEY=ollama
export HERMES_MODEL=gemma4:12b-mlx
EOF
source ~/.zshrc
# 6. 接続テスト
hermes chat --prompt "hello from local"Claude Code から Hermes Agent を呼ぶ場合は、~/.claude/mcp.json に Ollama 経由の Hermes をエントリ追加するだけで、Claude 側から自然にローカルモデルへスイッチできます。
ローカル LLM の限界と注意点
正直に書きます。私たちが現場で踏んだ「ローカル LLM の壁」は次のとおりです。
- コンテキスト長:実用ラインは 32K〜128K。社内マニュアル全体を 1 リクエストで投げるのは厳しい。RAG 前提で設計する
- 複雑な多段推論:要件整理 → 設計 → コード生成を 1 ショットでやらせると Claude Opus との差が出る
- 日本語 Function Calling:Gemma 4 12B でも稀に JSON 整形を崩す。プロンプトに strict 指示を入れる
- 長時間連続稼働:Mac mini を 24h 回すと夏場はサーマルが効く。冷却 or 業務時間限定運用が無難
裏を返せば、上記の弱い領域だけクラウドに任せ、それ以外をローカルで処理すれば、月数千円〜数万円の API コストで Hermes Agent をフル活用できます。
まとめ
2026 年現在、Hermes Agent を Ollama でローカル運用するハードルは大きく下がりました。Gemma 4 12B MLX を Mac mini M4 24GB に乗せるだけで、日常の 8 割は外部 API ゼロでこなせます。残り 2 割の重要タスクだけクラウドに回すハイブリッド設計が、コストと機密性と精度のバランスが最も良い構成だと私たちは考えています。私たちが伴走する案件でも、まずローカル Ollama を立てて、現場の業務を流し込みながら段階的にクラウドへ逃がす設計を標準にしています。手元のマシンに Ollama を入れるところから、ぜひ試してみてください。
Hermes Agentに「任せる」前に読む本
料金の構造・構成の選び方・任せる前の柵——導入前の調査を全部(全22ページ)
本体は無料でも、財布は裏側に3つあります。料金の構造、直置きしない構成の選び方、そしてAIエージェントの実運用で毎日使っている「任せる前の柵」まで——入れるか見送るかを、この1冊で決められるようにまとめました。
- 費用の3層構造(本体0円・箱代・頭脳代)と隠れコスト4つ
- 直置きNG——安全性で選ぶ実行環境4パターン
- お金と送信を触らせない「3段階の柵」
- 4つの質問で決める、導入判断シートつき
毎週金曜の無料ニュースレター「ひとりAI経営」の購読特典です。メール登録後すぐ、ダウンロードページのご案内が届きます。あわせて、AI活用に関するお知らせやお役に立てそうなご案内をお送りすることがあります。解除はいつでも1クリック。
Hermes Agent を本気で活用するなら
「Hermes Agent を自分で使いこなしたい」「自社の業務に組み込みたい」
— そんな方は、まず初回無料相談でお話ししてみませんか。