Hermes Agentの3層メモリと永続記憶|育つAIの仕組み

Hermes Agent のメモリは、短期・中期・永続の3層構造で設計されており、これが「使い込むほど賢くなる」エージェント体験の核心になっています。本記事では、Hermes Agent の3層メモリと永続記憶のアーキテクチャを技術的に分解し、Claude Code や LangGraph など他基盤との違い、海外利用者の決定的な証言、そして運用上の落とし穴までを通しで解説します。AI エージェントの永続記憶を業務に組み込みたい開発者・技術選定者にとっての判断材料を一気に渡します。
Hermes Agent のメモリが「育つAI」と呼ばれる理由
Nous Research が 2026年2月に公開した Hermes Agent は、公式のローンチアナウンスで "the open source agent that grows with you... multi-level memory system and persistent dedicated machine access" と紹介されました。「あなたとともに育つエージェント」というキャッチコピーが看板倒れではないと言える根拠の中心にあるのが、本記事で扱う3層メモリです。
従来の対話型 LLM の限界は明確でした。セッションが終われば文脈が消える、別ウィンドウに移れば再説明が必要になる、長期プロジェクトで一貫した文体や知識を保てない。Hermes Agent はこの限界を、メモリの層を分けて保持期間と役割を変えることで突破しています。
株式会社Fyveでも Hermes Agent を自動化検証で扱っていますが、3層メモリは単に技術的に面白いだけでなく、案件単位の文脈と組織横断の知見を切り分けて運用できる、実務上の大きな分岐点になっています。
「育つ」体感はどこから来るのか
海外で最も引用される証言の一つが、X 上の @techNmak が 2026年4月7日に投稿した次の一文です。
"10 days ago I installed an open-source agent. Today it knows my codebase better than I do."(10日前にオープンソースのエージェントを入れた。今日、それは私自身よりこのコードベースを理解している)
これは単なるリップサービスではありません。Hermes Agent は対話のたびに重要な事実・決定・コード構造の解釈を中期・永続の層に振り分け、後続のセッションでもそれらを文脈に積み上げていきます。10日間の利用ログそのものが、エージェント側に蓄積される設計です。
3層メモリの定義と役割
Hermes Agent のメモリは大きく3層に分かれています。それぞれの保持期間と目的を整理します。

短期メモリ(Working Memory)
- 保持期間: 単一セッション・単一タスク内のみ
- 役割: 現在進行中の作業に必要な直近の文脈、ツール実行結果、ユーザーからの直近の指示
- 実装イメージ: LLM のコンテキストウィンドウに直接乗っているトークン群。タスク完了とともに揮発する
- 必須要件: モデル側が 64,000 トークン以上のコンテキストを持つこと(公式必須要件)
短期メモリは「今この瞬間の作業卓」に近い概念です。ファイル編集中のバッファ、コマンド実行の出力、ユーザーとの数往復の対話などが該当します。ここに長期情報を載せ続けるとコンテキストを圧迫するため、Hermes Agent は重要なものだけを中期・永続へ昇格させる設計を取ります。
中期メモリ(Session Memory)
- 保持期間: セッションをまたいで一定期間。プロジェクト単位の存続期間と一致するイメージ
- 役割: 現在進行中のプロジェクトの目的、これまでの決定事項、未解決の課題、サブエージェントへの引き継ぎ事項
- 実装イメージ: プロジェクトディレクトリに紐付くメモリストア。サブエージェント間でも共有可能
中期メモリは、複数日にわたって続く案件で特に効きます。「先週話したあの仕様変更」「昨日まで詰まっていたエラーの解決状況」といった、長期記憶とまでは言えないが揮発させると面倒な情報を保持します。
永続メモリ(Persistent Memory)
- 保持期間: 明示的に削除するまで無期限
- 役割: ユーザーの恒常的な好み、文体、繰り返し参照されるドメイン知識、過去プロジェクトから抽出された再利用可能なパターン
- 実装イメージ: ローカルファイルシステム上のストア。Markdown ベースの knowledge ファイル、スキル定義、設定ファイル群
永続メモリの興味深い点は、エージェント自身がここに書き込みを行うことです。「次回からは私のコードレビューでは命名規則をこのルールで指摘してほしい」とユーザーが伝えれば、それを永続層に保存し、別セッション・別プロジェクトでも参照できます。
3層メモリの保持期間と昇格フロー
短期→中期→永続への情報の昇格は、Hermes Agent がタスク完了時や明示的なユーザー指示時に判断します。実務的には次のような流れになります。
- 短期で生まれ短期で消える情報: コマンドの実行結果、テストの出力、一時的な計算結果
- 短期→中期に昇格する情報: プロジェクトの設計判断、未解決のバグ、サブエージェントへの依頼内容
- 中期→永続に昇格する情報: 再利用可能なパターン(コーディング規約、文体ガイド、好きなツール構成)、ユーザーの恒常的な前提
この昇格フローは、人間の記憶のメタファーに近い設計です。今日扱った計算式は明日には忘れていいが、繰り返し使う公式や自分の癖は永続的に覚えておきたい。Hermes Agent はそれをエージェントとして実装しています。
自己改善スキルとの相乗効果
Hermes Agent の永続記憶は、自己改善スキル(Self-Evolving Skills)の仕組みと組み合わさったとき、本領を発揮します。
スキルが「育つ」プロセス
Hermes Agent には skill という再利用可能なタスク単位の概念があります。ユーザーが新しい作業を依頼すると、エージェントは既存スキルを参照しつつ、必要に応じて新しいスキルを生成・改善します。改善されたスキルは永続メモリに保存され、次回以降のセッションで自動的に利用されます。
2026年4月に Teknium 氏が発表した Hermes Curator は、この自己改善ループで生成されたスキルを自動統合・剪定する内蔵システムです。長期間運用していると、似たような skill が乱立して肥大化(skill bloat)する問題が起きるため、Curator が定期的に整理する役割を担います。
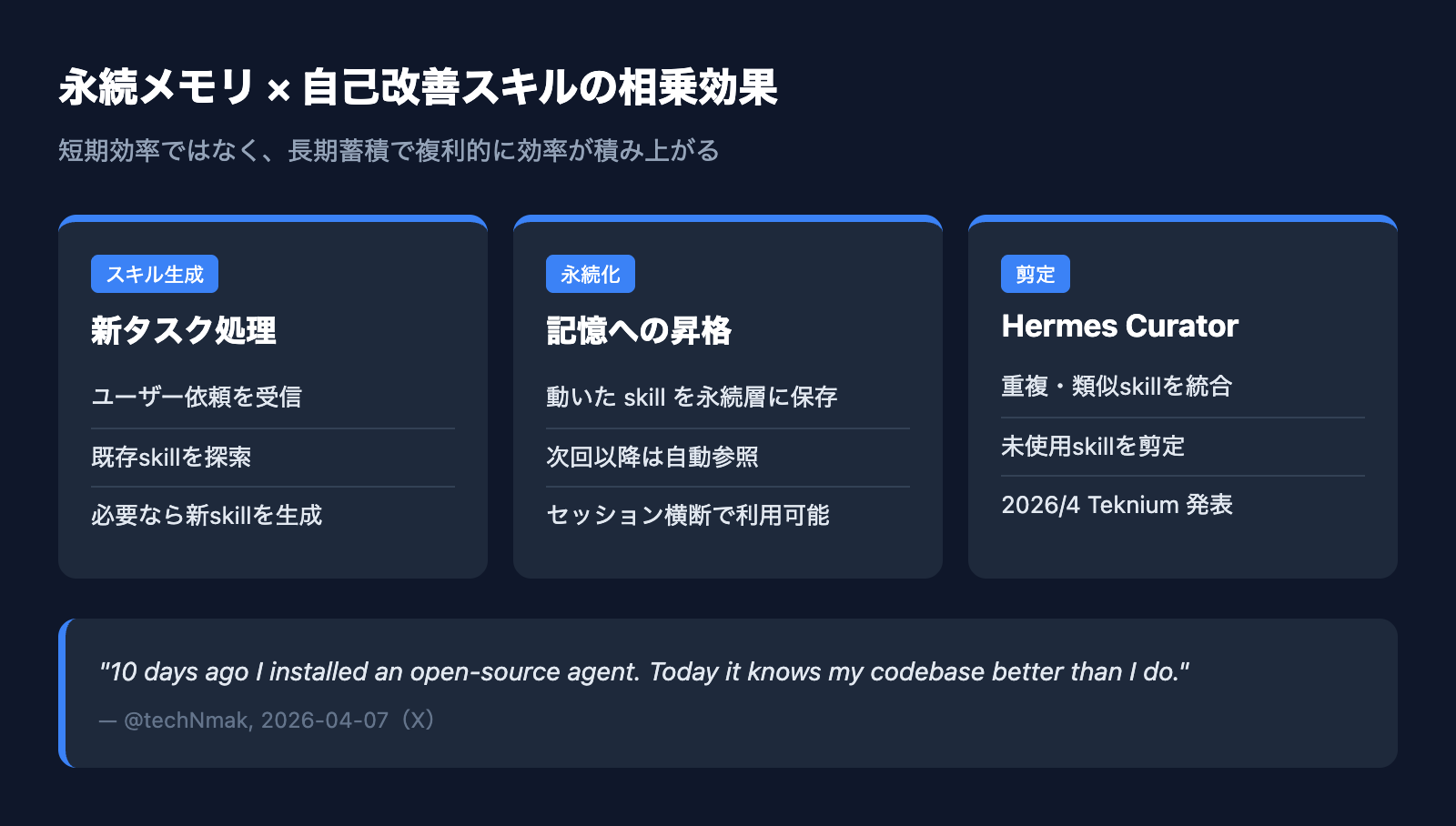
永続記憶 × スキル進化が生む長期効果
X の @NathanWilbanks_ は 2026年4月25日、Hermes Agent 導入から 297日目に「累計 900,000 秒超の compute 時間で、$100,000 相当の業務を自動化した」と報告しています。これは一過性のデモではなく、永続記憶とスキル進化の組み合わせが長期運用で複利的に効いていることを示す数字です。
1日あたりの単発効率ではなく、「過去に解決した類似タスクをほぼゼロコストで再実行できる」蓄積こそが、Hermes Agent のメモリ設計の真価です。
海外の実装事例から見るメモリの威力
3層メモリと永続記憶が実際にどう機能しているかは、海外の利用事例を見るのが最短ルートです。
事例1: 個人の文体を学習する LinkedIn 投稿エージェント
X の @Saboo_Shubham_ は 2026年4月29日、Hermes Agent に自分の過去 LinkedIn 記事を読み込ませ、文体・語彙・構成パターンを永続メモリに学習させた事例を公開しました。Mac Mini に常駐させ、新しい投稿アイデアを伝えると、本人のボイスを保ったままドラフトを生成します。
ここで重要なのは、文体分析の結果が「次回も同じプロンプトに毎回貼り付ける」必要がない点です。永続メモリに一度学習させれば、それ以降の生成は「あなたの過去の文体に従って書いて」という1行の依頼で動きます。
事例2: 子供への読み聞かせ物語の連続性
X の @kovern は、子供への読み聞かせ物語を Hermes Agent に生成させる用途で、過去のストーリー展開やキャラクター設定を永続メモリに保持させています。シリーズものの物語で「先週の続き」が破綻しないのは、中期メモリとして物語の世界観が、永続メモリとして登場人物の性格や関係性が保持されているからです。
事例3: Obsidian Vault との連携で長期知識ベース化
Reddit の @Jonathan_Rivera が 2026年4月23日に投稿した「Hermes Agent を Obsidian vault と接続して長期記憶バックボーンにする」事例は 794 upvotes を獲得しました。Obsidian の Markdown ファイル群そのものを永続メモリの実体として扱い、エージェントが読み書きできる設計です。
これにより、エージェントの記憶が人間にとっても可読・編集可能な状態で保たれる利点があります。「AI のブラックボックスにすべて任せる」のではなく、人間とエージェントが同じ Markdown ファイルを共有する協働モデルが成立します。
他のエージェント基盤とのメモリ比較
Hermes Agent のメモリ設計を相対化するために、他の主要なエージェント基盤と比較します。

Claude Code との比較
- Claude Code: Anthropic 純正。基本はセッション単位のコンテキスト。プロジェクトルートの
CLAUDE.mdや~/.claude/配下のメモリで部分的に永続化できるが、構造化された3層モデルではない - Hermes Agent: メモリの層が設計として明示され、自己改善スキルと連動して長期蓄積を前提に動く
私自身、Claude Code を日常運用していますが、永続記憶の扱いは「メモリファイルを自分でメンテナンスする」運用に近く、長期化すると整理が手間になります。Hermes Agent の Curator のような「剪定機構」が標準装備されているのは設計思想の差です。
LangGraph との比較
- LangGraph: フレームワーク。永続記憶を持たせたければ自分で実装する。Redis や PostgreSQL に状態を保存するなどの選択肢を組み合わせて設計する自由度が魅力
- Hermes Agent: 完成型ランタイム。インストール直後から3層メモリが動く。自分で設計する手間がない代わりに、メモリ仕様は Hermes Agent の流儀に従う
LangGraph はビルディングブロックを組む発想、Hermes Agent はパッケージとして動く発想です。永続記憶を「自分で設計したい」開発者には LangGraph、「すぐ運用に乗せたい」開発者には Hermes Agent という棲み分けになります。
運用上の注意点と落とし穴
3層メモリは便利な反面、運用していると次のような問題に直面します。
スキルの肥大化(Skill Bloat)
自己改善ループでスキルが量産されると、似たような skill が乱立し、エージェントが「どれを使うべきか」で迷う事象が起きます。Hermes Curator はこの問題への公式回答ですが、過信せず定期的に手動でレビューする運用が安全です。
永続メモリの剪定
永続メモリは無期限に残り続けるため、放置すると古い前提や使われなくなったルールが蓄積します。月次・四半期ペースで「もう使っていない記憶」を削除する剪定運用を推奨します。
機密情報の混入リスク
クライアント情報・個人情報を永続メモリに入れる運用は、漏洩リスクを上げます。3層メモリのどこに何を書くかは、情報の機密度を踏まえて設計してください。とくに永続層は「組織横断で残るべき汎用知識」に絞る運用が無難です。
Skill バージョン管理
自己改善で skill が更新されると、過去のセッションで動いていた挙動が変わる場合があります。重要な業務スキルは Git 等でバージョン管理し、ロールバック可能にしておくことを推奨します。
Fyve からの実装支援
株式会社Fyveでは、Hermes Agent をはじめとする自律エージェント基盤の検証・導入を支援しています。3層メモリの設計、永続記憶の運用ルール策定、自己改善スキルのガバナンス整備など、エージェントを「育てる」前提のアーキテクチャ設計をご相談いただけます。
Hermes Agent と他エージェント基盤の使い分けについて深掘りした記事もあわせてご覧ください。


まとめ
- Hermes Agent の3層メモリは 短期(セッション内)・中期(プロジェクト単位)・永続(無期限)で構成される
- 短期→中期→永続への昇格フローが、エージェントが「使い込むほど賢くなる」体感を生む
- 自己改善スキルと組み合わさると、長期運用で複利的に効率が積み上がる(@NathanWilbanks_ の 297日・$100K相当の事例)
- Claude Code はセッション単位、LangGraph は明示実装が必要。Hermes Agent は3層が標準装備
- 運用には Skill 肥大化・永続メモリの剪定・機密情報の混入リスクへの対応が必要
- Obsidian vault との連携(@Jonathan_Rivera 事例)のように、人間とエージェントが同じ知識基盤を共有する協働モデルが成立する
「使い込むほど賢くなる」は単なるマーケコピーではなく、3層メモリと自己改善スキルの組み合わせから生まれる構造的な性質です。導入を検討する際は、メモリの剪定運用と機密情報の扱いを最初から設計に組み込むことを推奨します。
Hermes Agent を本気で活用するなら
「Hermes Agent を自分で使いこなしたい」「自社の業務に組み込みたい」
— そんな方は、まず初回無料相談でお話ししてみませんか。