Obsidian vault×Hermes Agentで24時間動くAI秘書|794 upvotes事例

Obsidian の vault を、AIエージェントの長期記憶バックボーンとして使う —— このアイデアを Reddit に投稿して794 upvotesを集めた事例があります。投稿者は Reddit ユーザーの @Jonathan_Rivera、日付は2026年4月23日。「24時間動く AI 秘書が欲しい」というニーズに対して、Obsidian と Hermes Agent を組み合わせるアプローチが多くの開発者の共感を呼びました。株式会社Fyveは中小企業向けのAI業務効率化を主業務にしており、この事例は「個人ナレッジをそのまま AI 秘書に渡せるか」という観点で実務的に重要だと考えています。本記事ではこの事例の構造と、私たちが現場でどう応用できるかを分解します。
事例の概要
まず事実関係を3点で押さえます。
- 誰: @Jonathan_Rivera(Reddit r/LocalLLaMA で活動するユーザー)
- いつ: 2026年4月23日の投稿
- 何: Obsidian vault を Hermes Agent の長期記憶層として連携させる構成の提案・実装報告
反響を示す数字は次のとおりです。
指標 | 数値 | 備考 |
|---|---|---|
upvotes | 794 | r/LocalLLaMA 上の投稿時点 |
投稿日 | 2026-04-23 | Hermes Agent v0.11.0 公開と同日帯 |
核となる発想 | vault = 長期記憶 | 個人ナレッジを外部知識層として扱う |
出典は Reddit r/LocalLLaMA の議論スレッドです。この事例が「24時間動く AI 秘書が欲しい」というニーズに刺さって 800 近い upvotes を集めたことは、欲求の存在と解決アプローチの妥当性を裏付ける一次データだと私たちは見ています。

Obsidian vault × Hermes Agent の永続記憶バックボーン化
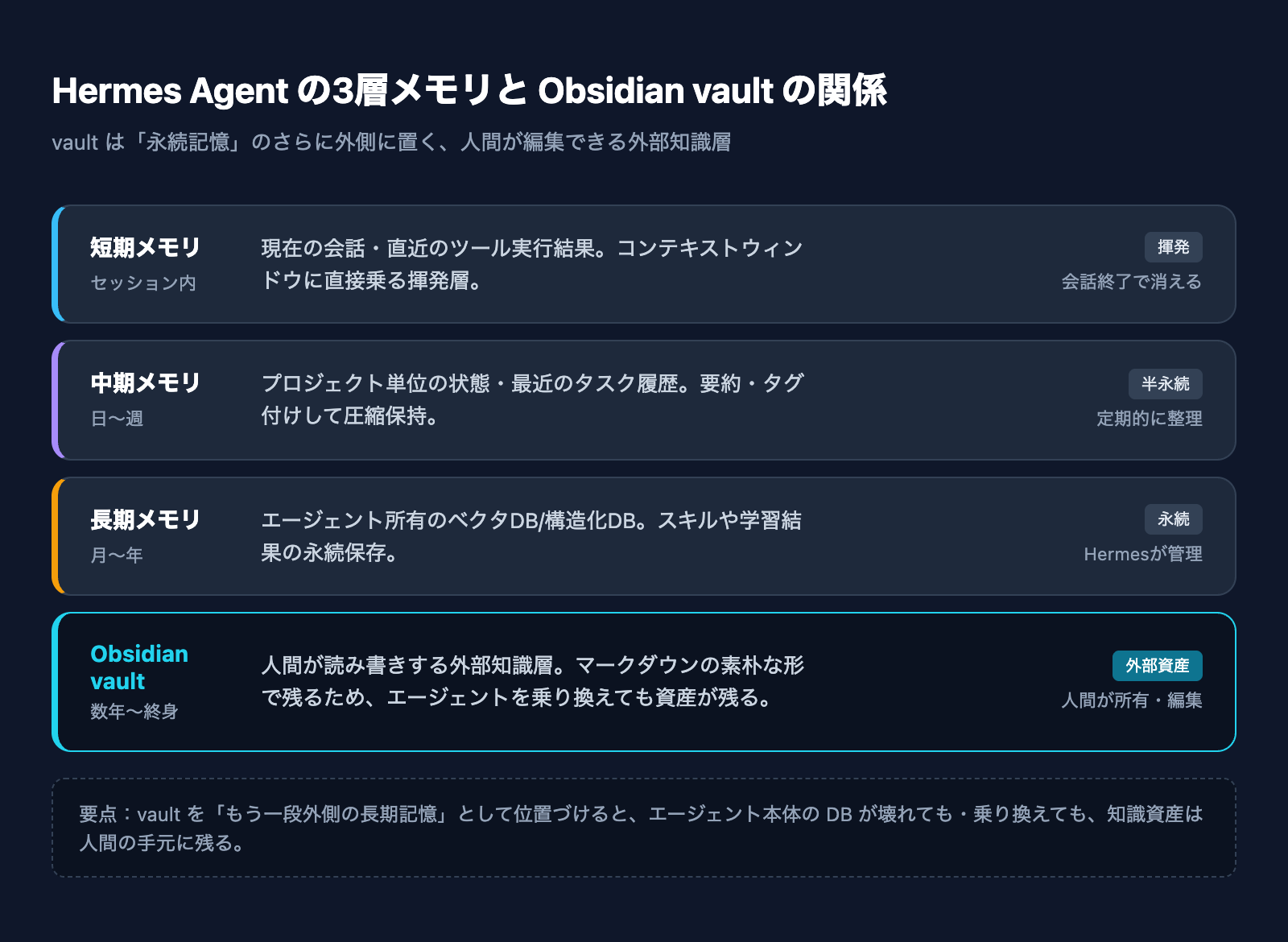
この事例の核心は、Obsidian vault を「人間が読み書きするメモ」と「AIエージェントが参照する長期記憶DB」の兼用ストレージとして扱う点にあります。
Obsidian は、マークダウンファイルをローカルフォルダ(vault)に格納し、ファイル間を内部リンク・バックリンク・タグで結びつけるナレッジツールです。技術者・研究者・ライター層に深く浸透しており、数年単位で日次メモ・議事録・読書ログ・コードスニペットを蓄積している利用者が多数います。
一方の Hermes Agent は、2026年2月に Nous Research が公開したオープンソースの自律エージェントランタイムです。短期・中期・永続の3層メモリを内蔵し、セッションを跨いで記憶を保持する設計を持ちます。@Jonathan_Rivera のアプローチは、ここにもう一段外側のメモリ層として vault を接続する、というものです。
連携の構造を整理すると、こうなります。
- Hermes Agent は vault の中のマークダウンファイルを読み込み、自分の長期記憶として参照する
- 新たな出来事・学習結果は、エージェントが vault にマークダウンで書き戻す
- 人間はいつもどおり Obsidian を開いて、vault を読み書きする
- vault は人間にとってもAIにとっても、同じ知識ベースになる
つまり、エージェントが内部に閉じこもったベクタDBだけで記憶を持つのではなく、人間が編集できる外部資産を一次情報源として共有するという発想です。
なぜ「永続記憶バックボーン化」が刺さったのか — 私たちの解釈
Reddit で 794 upvotes を集めたという事実は、技術コミュニティが何に飢えているかを示すシグナルです。この事例から私たちが読み取った論点は3つあります。
第一に、「24時間動く AI 秘書」を欲しい層は、すでに自分のナレッジを Obsidian に貯めている。 ゼロから AI に教え込むのではなく、いま手元にある知識資産をそのまま渡したい、という具体的なニーズが背景にあります。新しい仕組みのために自分の書き方を変えるのではなく、すでに毎日書いているメモがそのまま AI の燃料になる、というのが刺さった理由です。
第二に、エージェント本体に記憶を依存させたくない、という設計上の警戒感がある。 Hermes Agent 自体はオープンソースですが、永続記憶DBの実体はベクタDBや独自フォーマットになりがちで、エージェントを乗り換えると記憶資産を失うリスクがあります。vault に書き戻しておけば、エージェント側がどう変わっても、知識はマークダウンの素朴な形で人間の手元に残ります。これは「ベンダーロックイン回避」の発想を、エージェント層に持ち込んだものと言えます。
第三に、AIに対する「所有権の主張」として機能している。 エージェントの長期記憶を vault に置くというのは、技術的な選択であると同時に、「これは自分のメモであり自分の知識資産である」という宣言でもあります。AIに何でも委ねるのではなく、人間が編集権を持ち続ける構成にする、という運用思想がコミュニティ層に響いたと私たちは見ています。
この設計は、中小企業の現場でも転用可能です。社内に散らばっている議事録・対応履歴・ノウハウメモを vault に寄せておけば、エージェントを差し替えても会社の知識資産は残ります。私たちが企業に AI 担当者として伴走する際にも、まず「会社の vault に相当する場所」を1か所決めることを最初の設計にしています。
実務への落とし込み — 個人ナレッジを Hermes で再利用する手順
では、@Jonathan_Rivera の発想を実際に手を動かして再現するとき、どう設計すればよいでしょうか。中小企業の現場や個人の業務に持ち込むことを想定して、私たちが推奨する手順を示します。
初期セットアップで決めておくこと
- vault の場所: ローカルフォルダの絶対パスを決める。Hermes Agent からの読み書きを許可するパスはこの1つに絞り、他の領域には触らせない
- ファイル命名規約: 日次ノートは
YYYY-MM-DD.md、トピックノートは kebab-case、議事録はmeeting-{date}-{topic}.mdなど、エージェントが推論しやすい命名に統一する - 書き戻しフォルダ: エージェントが新規生成するノートは
_agent_inbox/など専用フォルダに置く。人間が確認してから vault 本体に取り込む運用にすると安全 - タグ運用:
#task,#decision,#questionなど、エージェントが拾いやすい意味タグを最初に決めておく - 除外パス: 顧客個人情報・金額・契約書原本など、エージェントに読ませたくないファイルは
private/配下に隔離し、Hermes 側で除外設定する
運用フェーズで起きること
運用を始めると、人間の「メモを書く動作」とエージェントの「メモを参照する動作」が同じ vault の上で同居します。代表的な使われ方は以下です。
- 朝の問いかけ: 「昨日の議事録を読んで、今日のタスクリストを作って」と Hermes に指示すると、vault の昨日の日付ファイルから抽出してくれる
- 過去の決定の検索: 「半年前に〇〇という顧客と話したときの結論は?」と聞くと、vault 全体を横断して該当ノートを引いてくる
- 新規ノートの起草: ミーティング後に音声を流し込めば、エージェントが議事録の初稿を vault に書き戻す。人間は内容を整える編集者の役割に回る
- 学びの自動蓄積: エージェントが調べ物をした結果を「学習ログ」として vault に追記しておけば、次回以降は人間も AI も同じ参照先を持てる
運用で詰まりやすい落とし穴
- vault の肥大化: エージェントが書き戻すノートが増えすぎると検索精度が落ちる。月次で「アーカイブ」フォルダに古いノートを移す運用を組み込む
- タグの揺れ: 人間とAIで異なるタグ表記が混在すると分類が崩れる。タグ用語集を vault 内に1ファイル置いて、それをエージェントにも参照させる
- 機密情報の流出: vault 内に意図せず機密ファイルが入ってしまうと、エージェント経由で外部 LLM に送られる可能性がある。除外パス設定を必ず初期段階で固める
- 同期の衝突: 人間が編集中に Hermes が同じファイルを書き換えるとマージ衝突が起きる。書き戻し先は別フォルダに分けるのが鉄則
中小企業に応用する場合、vault は個人の Obsidian である必要はなく、社内 Wiki・Notion・Google Drive 上の Markdown フォルダなどでも同じ思想で運用できます。重要なのは、知識がエージェント所有のブラックボックスDBに入りきらない場所に置かれていることです。
関連事例 — 同じ思想で動く先行事例
「個人ナレッジを永続記憶バックボーンに使う」というアプローチは、@Jonathan_Rivera のものが代表例ではあるものの、近い設計で動いている事例が他にもあります。
- @jezza2463(2026-03-29): Hermes Agent で Obsidian の日次ジャーナルを自動生成・追記する運用。1日の出来事をエージェントに口述してマークダウン化する
- @Saboo_Shubham_(2026-04-29): 過去のLinkedIn記事を文体素材として読み込ませ、Mac Mini 常駐 + 永続記憶で「自分の声」を保ったまま個人投稿を自動生成
- @trevorgordon981: Mac Studio 常駐 + iMessage 連携で、Apple Watch / iPhone / iPad を跨いで同じエージェントに話しかける構成。記憶は端末を超えて1本化されている
- Anthony Maio(2026-03-30): Slack inbox の要約を自然言語の cron 指示で自動化。「平日9amにinbox要約してSlackに投げて」というレベルの指示が成立する
これらに共通するのは、エージェントの記憶を「人間が見えない場所」ではなく「人間がいつも開く場所」に置いている点です。Obsidian vault・日次ジャーナル・過去のLinkedIn記事・iMessage 履歴 —— いずれも人間側に編集権がある外部資産であり、そこを長期記憶バックボーンとして再利用しています。

まとめ
- @Jonathan_Rivera の Reddit 投稿(2026-04-23)は、Obsidian vault を Hermes Agent の長期記憶バックボーンに使う構成を提案し、794 upvotes を獲得した
- 核となる発想は、エージェント所有の DB ではなく、人間が編集できる外部資産(vault)に長期記憶を置くこと
- 反響が大きかった理由は、すでにナレッジを Obsidian に貯めている層に対して「既存の資産をそのまま AI に渡せる」価値を提示できたから
- エージェント乗り換え時に記憶資産を失わない、ベンダーロックイン回避の設計としても機能する
- 中小企業に転用する場合、vault は Obsidian でなくともよく、社内 Wiki や共有 Markdown フォルダでも同じ思想で運用できる
- 運用設計の急所は、命名規約・書き戻しフォルダの分離・除外パス設定・タグ用語集の4点
- 同じ思想の先行事例(@jezza2463 / @Saboo_Shubham_ / @trevorgordon981 など)が積み上がりつつあり、「育つAI」を中長期で運用する標準パターンになりつつある
Hermes Agent を本気で活用するなら
「Hermes Agent を自分で使いこなしたい」「自社の業務に組み込みたい」
— そんな方は、まず初回無料相談でお話ししてみませんか。